Chapitre 13 Méthodes de classification non supervisée
Dans le cadre de ce chapitre, nous présentons les méthodes les plus utilisées en sciences sociales pour explorer la présence de groupes homogènes au sein d’un jeu de données, soit les méthodes de classification non supervisée. Le qualificatif non supervisé signifie que ces classes/groupes ne sont pas connus a priori et doivent être identifiés à partir des données. Autrement dit, nous cherchons à regrouper les observations partageant des caractéristiques similaires sur la base de plusieurs variables. Ces méthodes descriptives et exploratoires multivariées peuvent être vues comme une façon de réduire le nombre d’observations d’un jeu de données à un ensemble d’observations synthétiques, représentant le mieux possible la population à l’étude.
Dans ce chapitre, nous utilisons les packages suivants :
- Pour créer des graphiques :
ggplot2le seul, l’unique!ggpubrpour combiner des graphiques et réaliser des diagrammes.
- Outils généraux pour faciliter les classifications :
clusterCritpour calculer des indicateurs de qualité de classification.NbClustpour trouver le bon nombre de groupe dans une classification.clusterpour appliquer la méthode GAP.proxypour calculer plusieurs types de distances.Gmedianpour calculer le k-médianes.geocmeanspour explorer les résultats de classifications floues.
Pourquoi recourir à des méthodes de classification non supervisée en sciences sociales?
Les méthodes de classification sont très utilisées en sciences sociales. Elles visent à identifier des groupes cohérents au sein d’un ensemble d’observations sur la base de plusieurs variables (figure 13.1). Ces groupes peuvent ensuite être analysés et nous renseigner sur les caractéristiques communes partagées par les individus qui les composent.
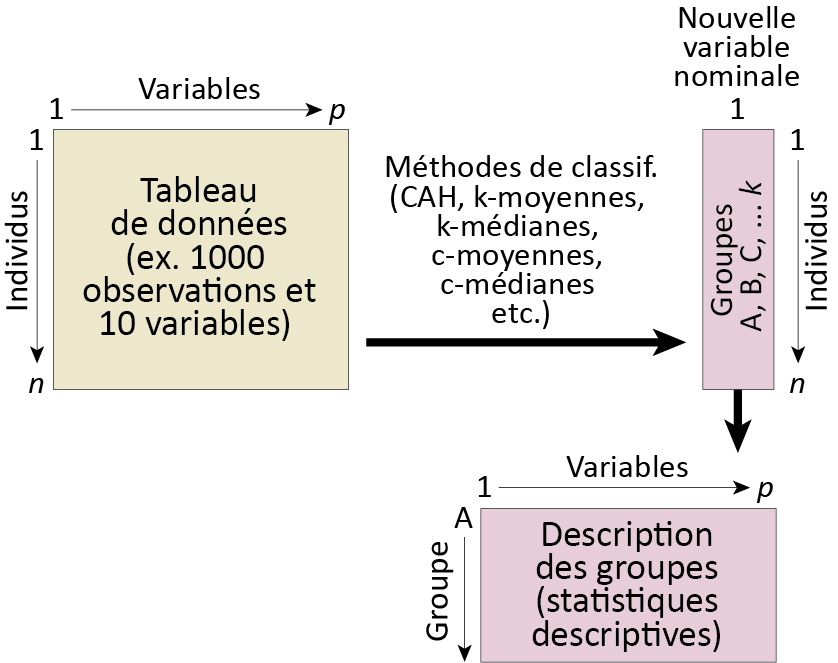
Figure 13.1: Principe de base des méthodes de classification non supervisée
Un exemple classique est l’identification de profils d’individus ayant répondu à un sondage, en fonction de plusieurs caractéristiques (par exemple, l’âge, le sexe, la situation de famille, le revenu, etc.). En identifiant ces groupes homogènes, il est ensuite possible d’explorer les associations entre ces profils et d’autres variables.
Un second exemple serait de regrouper les secteurs d’une ville selon leurs caractéristiques environnementales (végétation, niveau de bruit, pollution atmosphérique, etc.) et socioéconomiques (revenu médian des ménages, pourcentage d’immigrants, pourcentage de personnes à faible scolarité, taux de chômage, etc.).