1.1 Histoire et philosophie de R
R est à la fois un langage de programmation et un logiciel libre (sous la licence publique générale GNU) dédié à l’analyse statistique et soutenu par une fondation : R Foundation for Statistical Computing. Il est principalement écrit en C et en Fortran, deux langages de programmation de « bas niveau », proches du langage machine. À l’inverse, R est un langage de « haut niveau », car plus proche du langage humain.
R a été créé par Ross Ihaka et Robert Gentleman à l’Université d’Auckland en Nouvelle-Zélande. Si vous avez un jour l’occasion de passer dans le coin, une plaque est affichée dans le département de statistique de l’université; ça mérite le détour (figure 1.1). Une version expérimentale a été publiée en 1996, mais la première version stable ne date que de 2000. Il s’agit donc d’un logiciel relativement récent si nous le comparons à ses concurrents SPSS (1968), SAS (1976) et Stata (1984).

Figure 1.1: Lieu de pèlerinage de R
R a cependant réussi à s’imposer tant dans le milieu de la recherche que dans le secteur privé. Pour s’en convaincre, il suffit de lire l’excellent article concernant la popularité des logiciels d’analyse de données tiré du site r4stats.com (figure 1.2).
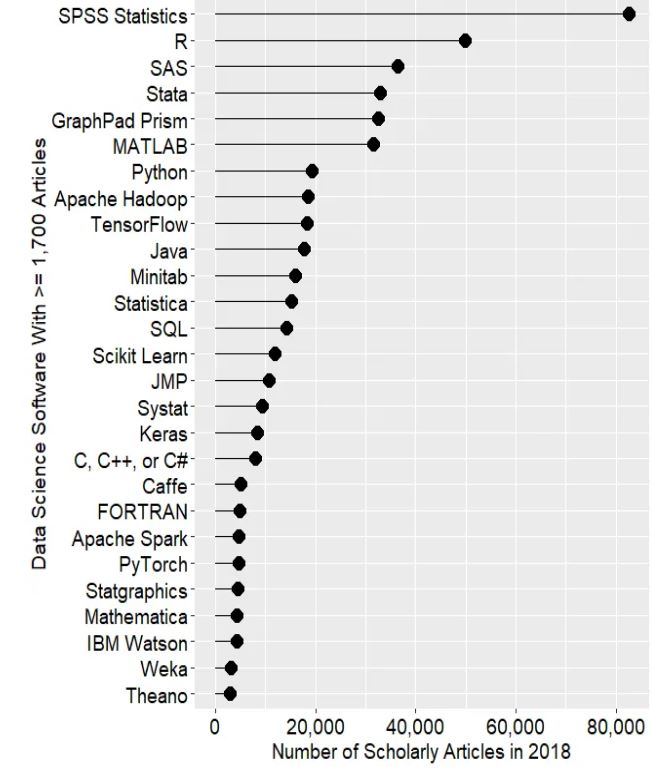
Figure 1.2: Nombre d’articles trouvés sur Google Scholar (source : Robert A. Muenchen)
Les nombreux atouts de R justifient largement sa popularité sans cesse croissante :
- R est un logiciel à code source ouvert (open source) et ainsi accessible à tous gratuitement.
- Le développement du langage R est centralisé, mais la communauté peut créer et partager facilement des packages. Les nouvelles méthodes sont ainsi rapidement implémentées comparativement aux logiciels propriétaires.
- R est un logiciel multiplateforme, fonctionnant sur Linux, Unix, Windows et Mac.
- Comparativement à ses concurrents, R dispose d’excellentes solutions pour manipuler des données et réaliser des graphiques.
- R dispose de nombreuses interfaces lui permettant de communiquer, notamment avec des systèmes de bases de données SQL et non SQL (MySQL, PostgresSQL, MongoDB, etc.), avec des systèmes de big data (Spark, Hadoop), avec des systèmes d’information géographique (QGIS, ArcGIS) et même avec des services en ligne comme Microsoft Azure ou Amazon AWS.
- R est un langage de programmation à part entière, ce qui lui donne plus de flexibilité que ses concurrents commerciaux (SPSS, SAS, STATA). Avec R, vous pouvez accomplir de nombreuses tâches : monter un site web, créer un robot collectant des données en ligne, combiner des fichiers PDF, composer des diapositives pour une présentation ou même éditer un livre (comme celui-ci), mais aussi, et surtout, réaliser des analyses statistiques.
Un des principaux attraits de R est la quantité astronomique de packages actuellement disponibles. Un package est un ensemble de nouvelles fonctionnalités développées par des personnes utilisatrices de R et mises à disposition de l’ensemble de la communauté. Par exemple, le package ggplot2 est dédié à la réalisation de graphiques; les packages data.table et dplyr permettent de manipuler des tableaux de données; le package car offre de nombreux outils pour faciliter l’analyse de modèles de régressions, etc. Ce partage de packages rend accessible à tous des méthodes d’analyses complexes et récentes et favorise grandement la reproductibilité de la recherche. Cependant, ce fonctionnement implique quelques désavantages :
- Il existe généralement plusieurs packages pour effectuer le même type d’analyse, ce qui peut devenir une source de confusion.
- Certains packages cessent d’être mis à jour au fil des années, ce qui nécessite de trouver des solutions de rechange (et ainsi apprendre la syntaxe de nouveaux packages).
- Il est impératif de s’assurer de la fiabilité des packages que vous souhaitez utiliser, car n’importe qui peut proposer un package.
Il nous semble important de relativiser d’emblée la portée du dernier point. Il est rarement nécessaire de lire et d’analyser le code source d’un package pour s’assurer de sa fiabilité. Nous ne sommes pas des spécialistes de tous les sujets et il peut être extrêmement ardu de comprendre la logique d’un code écrit par une autre personne. Nous vous recommandons donc de privilégier l’utilisation de packages qui :
- ont fait l’objet d’une publication dans une revue à comité de lecture ou qui ont déjà été cités dans des études ayant fait l’objet d’une publication revue par les pairs;
- font partie de projets comme ROpensci prônant la vérification par les pairs ou subventionnés par des organisations comme R Consortium;
- sont disponibles sur l’un des deux principaux répertoires de packages R, soit CRAN et Bioconductor.
Toujours pour nuancer notre propos, il convient de distinguer package de package! Certains d’entre eux sont des ensembles très complexes de fonctions permettant de réaliser des analyses poussées alors que d’autres sont des projets plus modestes dont l’objectif principal est de simplifier le travail des personnes utilisant R. Ces derniers ressemblent à de petites boîtes à outils et font généralement moins l’objet d’une vérification intensive.
Pour conclure cette section, l’illustration partagée sur Twitter par Darren L Dahly résume avec humour la force du logiciel R et de sa communauté (figure 1.3) : R apparaît clairement comme une communauté hétéroclite, mais diversifiée et adaptable.

Figure 1.3: Métaphore sur les langages et programmes d’analyse statistique
Dans ce livre, nous détaillons les packages utilisés dans chaque section avec un encadré spécifique, accompagné de l’icône présentée à la figure 1.4.

Figure 1.4: Icône des encadrés dédiés aux packages