2.1 Notion et types de variable
2.1.1 Notion de variable
D’un point de vue empirique, une variable est une propriété, une caractéristique d’une unité statistique, d’une observation. Il convient alors de bien saisir à quelle unité d’analyse (ou unité d’observation) s’appliquent les valeurs d’une variable : des personnes, des ménages, des municipalités, des entreprises, etc. Par exemple, pour des individus, l’âge, le genre ou encore le revenu sont autant de caractéristiques qui peuvent être mesurées à partir de variables. Autrement dit, une variable permet de mesurer un phénomène (dans un intervalle de valeurs, c’est-à-dire de manière quantitative) ou de le qualifier (avec plusieurs catégories, c’est-à-dire de manière qualitative).
D’un point de vue plus théorique, une variable permet d’opérationnaliser un concept en sciences sociales (Gilles et Maranda 1994, 30), soit une « idée générale et abstraite que se fait l’esprit humain d’un objet de pensée concret ou abstrait, et qui lui permet de rattacher à ce même objet les diverses perceptions qu’il en a, et d’en organiser les connaissances » (Larousse). En effet, la construction d’un modèle théorique suppose d’opérationnaliser différents concepts et d’établir les relations qu’ils partagent entre eux. Or, l’opérationnalisation d’un concept nécessite soit de mesurer (dans un intervalle de valeurs, c’est-à-dire de manière quantitative), soit de qualifier (avec plusieurs catégories, c’est-à-dire de manière qualitative) un phénomène.
Maîtriser la définition des variables que vous utilisez : un enjeu crucial!
Ne pas maîtriser la définition d’une variable revient à ne pas bien saisir la caractéristique ou encore le concept sous-jacent qu’elle tente de mesurer. Si vous exploitez des données secondaires – par exemple, issues d’un recensement de population ou d’une enquête longitudinale ou transversale –, il faut impérativement lire les définitions des variables que vous souhaitez utiliser. Ne pas le faire risque d’aboutir à :
Une mauvaise opérationnalisation de votre modèle théorique, même si votre analyse est bien menée statistiquement parlant. Autrement dit, vous risquez de ne pas sélectionner les bonnes variables : prenons un exemple concret. Vous avez construit un modèle théorique dans lequel vous souhaitez inclure un concept sur la langue des personnes. Dans le recensement canadien de 2016, plusieurs variables relatives à la langue sont disponibles : connaissance des langues officielles, langue parlée à la maison, langue maternelle, première langue officielle parlée, connaissance des langues non officielles et langue de travail (https://www12.statcan.gc.ca/census-recensement/2016/ref/guides/003/98-500-x2016003-fra.cfm). La sélection de l’une de ces variables doit être faite de manière rigoureuse, c’est-à-dire en lien avec votre cadre théorique et suite à une bonne compréhension des définitions des variables. Dans une étude sur le marché du travail, nous sélectionnerions probablement la variable sur la connaissance des langues officielles du Canada, afin d’évaluer son effet sur l’employabilité, toutes choses étant égales par ailleurs. Dans une autre étude portant sur la réussite ou la performance scolaire, il est probable que nous utiliserions la langue maternelle.
Une mauvaise interprétation et discussion de vos résultats en lien avec votre cadre théorique.
Une mauvaise identification des pistes de recherche.
Finalement, la définition d’une variable peut évoluer à travers plusieurs recensements de population : la société évolue, les variables aussi! Par conséquent, si vous comptez utiliser plusieurs années de recensement dans une même étude, assurez-vous que les définitions des variables sont similaires d’un jeu de données à l’autre et qu’elles mesurent ainsi la même chose.
Comprendre les variables utilisées dans un article scientifique : un exercice indispensable dans l’élaboration d’une revue de littérature
Une lecture rigoureuse d’un article scientifique suppose, entre autres, de bien comprendre les concepts et les variables mobilisés. Il convient alors de lire attentivement la section méthodologique (pas uniquement la section des résultats ou pire, celle du résumé), sans quoi vous risquez d’aboutir à une revue de littérature approximative. Ayez aussi un regard critique sur les variables utilisées en lien avec le cadre théorique. Certains concepts sont très difficiles à traduire en variables; leurs opérationnalisations (mesures) peuvent ainsi faire l’objet de vifs débats au sein de la communauté scientifique. Très succinctement, c’est notamment le cas du concept de capital social. D’une part, les définitions et ancrages sont bien différents selon Bourdieu (sociologue, ancrage au niveau des individus) et Putman (politologue, ancrage au niveau des collectivités); d’autre part, aucun consensus ne semble clairement se dégager quant à la définition de variables permettant de mesurer le capital social efficacement (de manière quantitative).
Variable de substitution (proxy variable en anglais)
Nous faisons la moins pire des recherches! En effet, les données disponibles sont parfois imparfaites pour répondre avec précision à une question de recherche; nous pouvons toujours les exploiter, tout en signalant honnêtement leurs faiblesses et limites, et ce, tant pour les données que pour les variables utilisées.
Des bases de données peuvent être en effet imparfaites. Par exemple, en criminologie, lorsqu’une étude est basée sur l’exploitation de données policières, la limite du chiffre noir est souvent signalée : les données policières comprennent uniquement les crimes et délits découverts par la police et occultent ainsi les crimes non découverts; ils ne peuvent ainsi refléter la criminalité réelle sur un territoire donné.
Des variables peuvent aussi être imparfaites. Dans un jeu de données, il est fréquent qu’une variable ne soit pas disponible ou qu’elle n’ait tout simplement pas été mesurée. Nous cherchons alors une variable de substitution (proxy) pour la remplacer. Prenons un exemple concret portant sur l’exposition des cyclistes à la pollution atmosphérique ou au bruit environnemental. L’un des principaux facteurs d’exposition à ces pollutions est le trafic routier : plus ce dernier est élevé, plus les cyclistes risquent de rouler dans un environnement bruyant et pollué. Toutefois, il est rare de disposer de mesures du trafic en temps réel qui nécessitent des comptages de véhicules pendant le trajet des cyclistes (par exemple, à partir de vidéos captées par une caméra fixée sur le guidon). Pour pallier l’absence de mesures directes, plusieurs auteur(e)s utilisent des variables de substitution de la densité du trafic, comme la typologie des types d’axes (primaire, secondaire, tertiaire, rue locale, etc.), supposant ainsi qu’un axe primaire supporte un volume de véhicules supérieur à un axe secondaire.
2.1.2 Types de variables
Nous distinguons habituellement les variables qualitatives (nominale ou ordinale) des variables quantitatives (discrète ou continue). Tel qu’illustré à la figure 2.1, plusieurs mécanismes différents visent à qualifier, à classer, à compter ou à mesurer afin de caractériser les unités statistiques (observations) d’une population ou d’un échantillon.
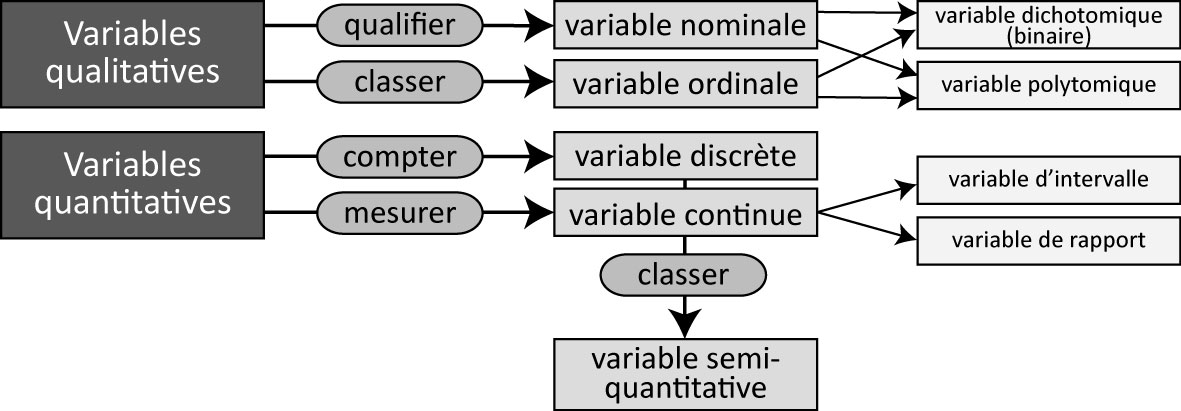
Figure 2.1: Types de variables
2.1.2.1 Variables qualitatives
Une variable nominale permet de qualifier des observations (individus) à partir de plusieurs catégories dénommées modalités. Par exemple, la variable couleur des yeux pourrait comprendre les modalités bleu, marron, vert, noir tandis que le type de famille compendrait les modalités couple marié, couple en union libre et famille monoparentale.
Une variable ordinale permet de classer des observations à partir de plusieurs modalités hiérarchisées. L’exemple le plus connu est certainement l’échelle de Likert, très utilisée dans les sondages évaluant le degré d’accord d’une personne à une affirmation avec les modalités suivantes : tout à fait d’accord, d’accord, ni en désaccord ni d’accord, pas d’accord et pas du tout d’accord. Une multitude de variantes sont toutefois possibles pour classer la fréquence d’un phénomène (très souvent, souvent, parfois, rarement, jamais), l’importance accordée à un phénomène (pas du tout important, peu important, plus ou moins important, important, très important) ou la proximité perçue d’un lieu (très éloigné, loin, plus ou moins proche, proche, très proche).
En fonction du nombre de modalités qu’elle comprend, une variable qualitative (nominale ou ordinale) est soit dichtomique (binaire) (deux modalités), soit polytomique (plus de deux modalités). Par exemple, dans le recensement canadien, le sexe est une variable binaire (avec les modalités sexe masculin, sexe féminin), tandis que le genre est une variable polytomique (avec les modalités genre masculin, genre féminin et diverses identités de genre).
Les variables nominales et ordinales sont habituellement encodées avec des valeurs numériques entières (par exemple, 1 pour couple marié, 2 pour couple en union libre et 3 pour famille monoparentale). Toutefois, aucune opération arithmétique (moyenne ou écart-type par exemple) n’est possible sur ces valeurs. Dans R, nous utilisons un facteur pour attribuer un intitulé à chacune des valeurs numériques de la variable qualitative :
df$Famille <- factor(df$Famille, c(1,2,3), labels = c("couple marié","couple en union libre", "famille monoparentale"))
Nous calculons toutefois les fréquences des différentes modalités pour une variable nominale ou ordinale. Il est aussi possible de calculer la médiane sur une variable ordinale.
2.1.2.2 Variables quantitatives
Une variable discrète permet de compter un phénomène dans un ensemble fini de valeurs, comme le nombre d’accidents impliquant un ou une cycliste à une intersection sur une période de cinq ans ou encore le nombre de vélos en libre service disponibles à une station. Il existe ainsi une variable binaire sous-jacente : la présence ou non d’un accident à l’intersection ou la disponibilité d’un vélo ou non à la station pour laquelle nous opérons un comptage. Habituellement, une variable discrète ne peut prendre que des valeurs entières (sans décimale), comme le nombre de personnes fréquentant un parc.
Une variable continue permet de mesurer un phénomène avec un nombre infini de valeurs réelles (avec décimales) dans un intervalle donné. Par exemple, une variable relative à la distance de dépassement d’un ou d’une cycliste par un véhicule motorisé pourrait varier de 0 à 5 mètres (\(X \in \left[0,5\right]\)); toutefois, cette distance peut être de 0,759421 ou de 4,785612 mètres. Le nombre de décimales de la valeur réelle dépend de la précision et de la fiabilité de la mesure. Pour un capteur de distance de dépassement, le nombre de décimales dépend de la précision du lidar ou du sonar de l’appareil; aussi, l’utilisation de trois décimales – soit une précision au millimètre – est largement suffisante pour mesurer la distance de dépassement. De plus, une variable continue est soit une variable d’intervalle, soit une variable de rapport. Les variables d’intervalle ont une échelle relative, c’est-à-dire que les intervalles entre les valeurs de la variable ne sont pas constants; elles n’ont pas de vrai zéro. Autrement dit, ce type de variable a une échelle relative avec un zéro arbitraire. Ces valeurs peuvent être manipulées uniquement par addition et soustraction et non par multiplication et division. La variable d’intervalle la plus connue est certainement celle de la température. S’il fait 10 degrés Celsius à Montréal et 30 °C à Mumbai (soit 50 et 86 degrés en Fahrenheit), nous pouvons affirmer qu’il y a 20 °C ou 36 °F d’écart entre les deux villes, mais ne pouvons pas affirmer qu’il fait trois fois plus chaud à Mumbai. Presque toutes les mesures statistiques sur une variable d’intervalle peuvent être calculées, exceptés le coefficient de variation et la moyenne géométrique puisqu’il n’y a pas de vrai zéro ni d’intervalles constants entre les valeurs. À l’inverse, les variables de rapport ont une échelle absolue, c’est-à-dire que les intervalles entre les valeurs sont constants et elles ont un vrai zéro. Elles peuvent ainsi être manipulées par addition, soustraction, multiplication et division. Par exemple, le prix d’un produit exprimé dans une unité monétaire ou la distance exprimée dans le système métrique sont des variables de rapport. Un vélo dont le prix affiché est de 1000 $ est bien deux fois plus cher qu’un autre à 500 $, une piste cyclable hors rue à 25 mètres du tronçon routier le plus proche est bien quatre fois plus proche qu’une autre à 100 mètres.
Une variable semi-quantitative, appelée aussi variable quantitative ordonnée, est une variable discrète ou continue dont les valeurs ont été regroupées en classes hiérarchisées. Par exemple, l’âge est une variable continue pouvant être transformée avec les groupes d’âge ordonnés suivants : moins 25 ans, 25 à 44 ans, 45 à 64 ans et 65 ans et plus.