2.2 Types de données
Différents types de données sont utilisés en sciences sociales. L’objectif ici n’est pas de les décrire en détail, mais plutôt de donner quelques courtes définitions. En fonction de votre question de recherche et des bases des données disponibles, il s’agit de sélectionner le ou les types de données les plus appropriés à votre étude.
2.2.1 Données secondaires versus données primaires
Les données secondaires sont des données qui existent déjà au début de votre projet de recherche : nul besoin de les collecter, il suffit de les exploiter! Une multitude de données de recensements ou d’enquêtes de Statistique Canada sont disponibles et largement exploitées en sciences sociales (par exemple, l’enquête nationale auprès des ménages – ENM, l’enquête sur la dynamique du marché du travail et du revenu – EDTR, l’enquête longitudinale auprès des immigrants – ELIC, etc.).
Au Canada, les personnes qui font de la recherche, qui étudient ou qui enseignent ont accès aux microdonnées des enquêtes de Statistique Canada dans les centres de données de recherche (CDR). Vous pouvez consulter le moteur de recherche du Réseau canadien des Centres de données de recherche (https://crdcn.org/fr/donn%C3%A9es) afin d’explorer les différentes enquêtes disponibles.
Au Québec, l’accès à ces enquêtes est possible dans les différentes antennes du Centre interuniversitaire québécois de statistiques sociales de Statistique Canada (https://www.ciqss.org/).
Par opposition, les données primaires n’existent pas quand vous démarrez votre projet : vous devez les collecter spécifiquement pour votre étude! Par exemple, une chercheure souhaitant analyser l’exposition des cyclistes au bruit et à la pollution dans une ville donnée doit réaliser une collecte de données avec idéalement plusieurs personnes participantes (équipées de différents capteurs), et ce, sur plusieurs jours. Une collecte de données primaires peut aussi être réalisée avec une enquête par sondage. Brièvement, réaliser une collecte de données primaires nécessite différentes phases complexes comme la définition de la méthode de collecte et de la population à l’étude, l’estimation de la taille de l’échantillon, la validation des outils de collecte avec une phase de test, la réalisation de la collecte, la structuration, la gestion et l’exploitation de données collectées. Finalement, dans le milieu académique, une collecte de données primaires auprès d’individus doit être approuvée par le comité d’éthique de la recherche de l’université à laquelle est affiliée la personne responsable du projet de recherche.
2.2.2 Données transversales versus données longitudinales
Les données transversales sont des mesures pour une période relativement courte. L’exemple classique est un jeu de données constitué des variables extraites d’un recensement de population pour une année donnée (comme celui de 2016 de Statistique Canada).
Les données longitudinales, appelées aussi données par panel, sont des mesures répétées pour plusieurs observations au cours du temps (N observations pour T dates). Par exemple, des observations pourraient être des pays, les dates pourraient être différentes années (de 1990 à 2019) pour lesquelles différentes variables seraient disponibles (population totale, taux d’urbanisation, produit intérieur brut par habitant, émissions de gaz à effet de serre par habitant, etc.).
2.2.3 Données spatiales versus données aspatiales
Les observations des données spatiales sont des unités spatiales géoréférencées. Elles peuvent être par exemple :
- des points (x,y) ou (lat-long) représentant des entreprises avec plusieurs variables (adresse, date de création, nombre d’employés, secteurs d’activité, etc.);
- les lignes représentant des tronçons de rues pour lesquels plusieurs variables sont disponibles (type de rue, longueur en mètres, nombre de voies, débit journalier moyen annuel, etc.);
- des polygones délimitant des régions ou des arrondissements pour lesquels une multitude de variables sociodémographiques et socioéconomiques sont disponibles;
- les pixels des bandes spectrales d’une image satellite.
À l’inverse, aucune information spatiale n’est disponible pour des données aspatiales.
2.2.4 Données individuelles versus données agrégées
Comme son nom l’indique, pour des données individuelles, chaque observation correspond à un individu. Les microdonnées de recensements ou d’enquêtes, par exemple, sont des données individuelles pour lesquelles toute une série de variables sont disponibles. Une étude analysant les caractéristiques de chaque arbre d’un quartier nécessite aussi des données individuelles : l’information doit être disponible pour chaque arbre. Pour les microdonnées des recensements canadiens, « chaque enregistrement au niveau de la personne comprend des identifiants (comme les identifiants du ménage et de la famille), des variables géographiques et des variables directes et dérivées tirées du questionnaire » (Statistique Canada). Comme signalé plus haut, ces microdonnées de recensements ou d’enquêtes sont uniquement accessibles dans les centres de données de recherche (CDR).
Les données individuelles peuvent être agrégées à un niveau supérieur. Prenons le cas de microdonnées d’un recensement. Les informations disponibles pour chaque individu sont agrégées par territoire géographique (province, région économique, division de recensement, subdivision de recensement, région et agglomération de recensement, secteurs de recensement, aires de diffusion, etc.) en fonction du lieu de résidence des individus. Des sommaires statistiques – basés sur la moyenne, la médiane, la somme ou la proportion de chacune des variables mesurées au niveau individuel (âge, sexe, situation familiale, revenu, etc.) – sont alors construits pour ces différents découpages géographiques (Statistique Canada).
L’agrégation n’est pas nécessairement géographique. En éducation, il est fréquent de travailler avec des données concernant les élèves, mais agrégées au niveau des écoles. La figure 2.2 donne un exemple simple d’agrégation de données individuelles.
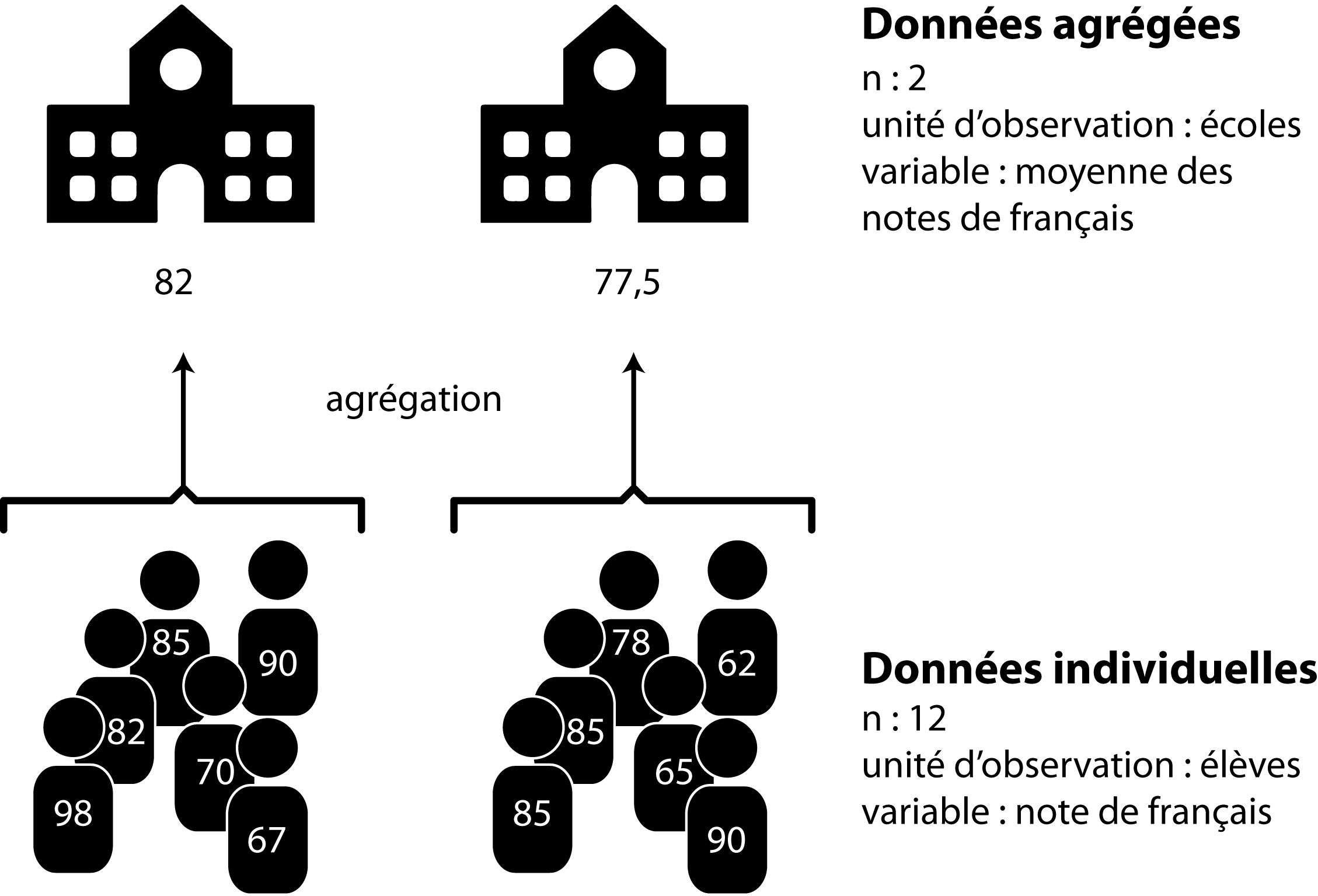
Figure 2.2: Exemple d’agrégation de données individuelles
Erreur écologique et erreur atomiste: attention aux interprétations abusives.
Il convient d’être prudent dans l’analyse des données agrégées. Très fréquente en géographie, l’erreur écologique (ecological fallacy en anglais) est une mauvaise interprétation des résultats. Elle consiste à attribuer des constats obtenus à partir de données agrégées pour un territoire aux individus qui forment la population de ce territoire. À l’inverse, attribuer des résultats à partir de données individuelles à des territoires est une erreur atomiste.
Prenons un exemple concret tiré d’une étude récente sur la localisation des écoles primaires et le bruit aérien dans la région métropolitaine de Toronto (Audrin, Apparicio et Séguin 2021). Un des objectifs de cette étude est de vérifier si les écoles primaires (ns = 1420) avec des niveaux de bruit aérien élevés présentent des niveaux de réussite scolaire plus faibles. Les résultats de leur étude démontrent que les enfants scolarisés dans les écoles primaires exposées à des niveaux élevés de bruit aérien sont issus de milieux plus défavorisés et ont plus souvent une langue maternelle autre que la langue d’enseignement. Aussi, les écoles avec des niveaux de bruit aérien élevés présentent des niveaux de réussite scolaire plus faibles.
Toutefois, étant donné que les variables sur la réussite scolaire sont mesurées au niveau de l’école (soit les pourcentages d’élèves ayant atteint ou dépassé la norme provinciale en lecture, en écriture et en mathématique, respectivement pour la 3e année et la 6e année) et non au niveau individuel, nous ne pouvons pas conclure que le bruit aérien à un impact significatif sur la réussite scolaire des élèves :
« Nous avons pu démontrer que les écoles primaires localisées dans la zone NEF 25 présentent des taux de réussite plus faibles. Rappelons toutefois qu’une association obtenue avec des données agrégées ne peut pas nous permettre de conclure à une influence directe au niveau individuel, car l’agrégation des données entraîne une perte d’information. Cette erreur d’interprétation dite erreur écologique (ecological fallacy) tend à laisser penser que les associations entre les groupes s’appliquent à chaque individu (Robinson, 1950). Nos résultats gagneraient à être corroborés à partir d’analyses reposant sur des données individuelles ».
Pour le cas de l’agrégation géographique, il convient alors de bien comprendre la hiérarchie des régions géographiques délimitées par l’organisme ou l’agence ayant la responsabilité de produire, de gérer et de diffuser les données des recensements et des enquêtes, puis de sélectionner le découpage géographique qui répond le mieux à votre question de recherche.
Pour le recensement de 2016 de Statistique Canada vous pouvez consulter :
- la hiérarchie des régions géographiques normalisées pour la diffusion (https://www12.statcan.gc.ca/census-recensement/2016/ref/dict/figures/f1_1-fra.cfm)
- le glossaire illustré (https://www150.statcan.gc.ca/n1/pub/92-195-x/92-195-x2016001-fra.htm) des régions géographiques
- les différents profils du recensement de 2016 à télécharger pour les différentes régions géographiques (https://www12.statcan.gc.ca/census-recensement/2016/dp-pd/prof/details/download-telecharger/comp/page_dl-tc.cfm?Lang=F).
Bien entendu, les différents types de données abordés ci-dessus ne sont pas exclusifs. Par exemple, des données pour des régions administratives extraites de plusieurs recensements sont en fait des données secondaires, spatiales, agrégées et longitudinales.
Une collecte de données sur la pollution atmosphérique et sonore réalisée à vélo (avec différents capteurs et un GPS) sont des données spatiales primaires.