13.4 Nuées dynamiques
Les méthodes des nuées dynamiques regroupent plusieurs algorithmes, tous plus ou moins liés avec l’algorithme le plus connu : k-means, originalement proposé par James MacQueen (1967). Nous présentons également ici plusieurs variantes du k-means, soit le k-medians, le k-medioids, le c-means et le c-medians.
13.4.1 K-means
13.4.1.1 Fonctionnement de l’algorithme
Nous commençons ici par détailler le fonctionnement de cet algorithme afin de mieux le cerner. D’emblée, cet algorithme nécessite que certains éléments soient définis d’avance :
- Une matrice de données X comportant n lignes (nombre d’observations) et p colonnes (nombre de variables). Chaque variable de cette matrice doit être quantitative et continue et de préférence dans une échelle standardisée (par exemple des variables centrées réduites).
- Le nombre de groupes à identifier k doit être choisi par l’utilisateur ou l’utilisatrice.
- La distance d à utiliser entre les observations.
Le fonctionnement classique du k-means est le suivant :
- Définir k centres de groupes de façon aléatoire.
- Déterminer pour chaque observation le centre de son groupe le plus proche en utilisant la fonction de distance.
- Pour chacun des groupes ainsi formés, recalculer le centre du groupe en calculant le centroïde (moyennes le plus souvent) des observations appartenant à ce groupe.
- Répéter l’opération 2 avec les nouveaux centres.
- Calculer l’inertie expliquée par la nouvelle classification.
- Comparer cette inertie expliquée avec celle obtenue lors de l’itération précédente.
- Si la variation entre les deux valeurs est supérieure à une certaine limite, reprendre à l’étape 2, sinon, l’algorithme prend fin.
Ainsi, l’algorithme k-means part d’une première classification obtenue aléatoirement et la raffine jusqu’au point où l’amélioration de la classification devient négligeable. Du fait de ce point de départ aléatoire, cet algorithme est dit heuristique, car deux exécutions risquent de ne pas donner exactement le même résultat. Par conséquent, en relaçant l’algorithme, vous pourriez obtenir des résultats légèrement différents, avec par exemple des groupes similaires, mais obtenus dans un autre ordre, le groupe 1 étant devenu le groupe 3 et vice-versa. Il est aussi possible d’obtenir des résultats radicalement différents d’une tentative à l’autre, ce qui signifie que les groupes formés sont très instables et ne sont pas représentatifs de la population étudiée.
Réplicabilité des résultats dans R
Lorsqu’une méthode heuristique ou faisant appel au hasard est utilisée dans R, il est nécessaire de s’assurer que les résultats sont reproductibles. Cela permet notamment de relancer le même code et de réobtenir exactement les mêmes résultats : l’idée étant de figer le hasard.
Ultimement, un programme informatique est incapable de générer un résultat véritablement aléatoire, car il ne fait que suivre une suite d’opérations prédéterminées. Pour générer des résultats qui ressemblent au hasard, des algorithmes ont été proposés, partant d’une configuration initiale et appliquant une série d’opérations complexes permettant de générer des nombres semblant se distribuer aléatoirement. Si nous connaissons le point de départ de la suite d’opérations et que nous réappliquons ces dernières, alors nous sommes certains d’obtenir le même résultat. Il est possible, dans R, de définir un état initial de hasard à l’aide de la fonction set.seed. Avec ce point de départ défini, nous sommes certains d’obtenir les mêmes résultats en relançant les mêmes opérations.
Prenons un exemple concret en sélectionnant aléatoire 3 chiffres dans un vecteur allant de 1 à 10.
vec <- 1:10
# prenons un premier échantillon
sample(vec, size = 3)## [1] 4 9 3# et un second échantillon
sample(vec, size = 3)## [1] 6 10 8Nous obtenons bien deux échantillons différents. Recommençons en utilisant la fonction set.seed pour obtenir cette fois-ci des résultats identiques.
vec <- 1:10
# prenons un premier échantillon
set.seed(123)
sample(vec, size = 3)## [1] 3 10 2# et un second échantillon
set.seed(123)
sample(vec, size = 3)## [1] 3 10 2# prenons un troisème échantillon
set.seed(4568997)
sample(vec, size = 3)## [1] 5 6 7# et un quatrième échantillon
set.seed(4568997)
sample(vec, size = 3)## [1] 5 6 7Vous constatez que nous utilisons cette fonction plusieurs fois au cours de cette section. Elle nous permet de nous assurer que les résultats obtenus ne changent pas entre le moment où nous écrivons le livre et le moment où nous le formatons. Sinon, le texte pourrait ne plus être en phase avec les images ou les tableaux.
Pour mieux comprendre le fonctionnement du k-means, nous proposons ici une visualisation de ses différentes itérations.
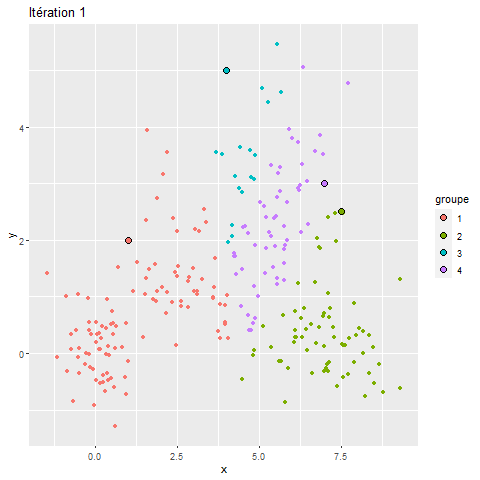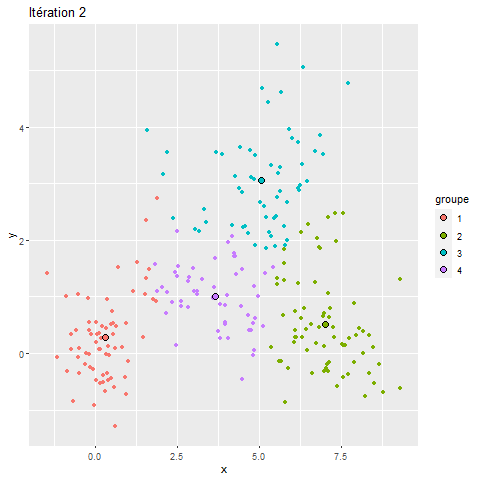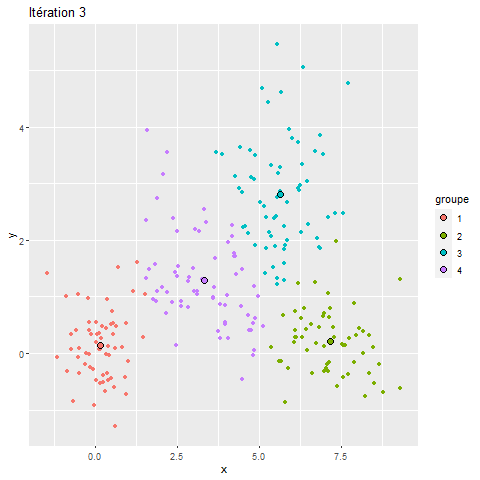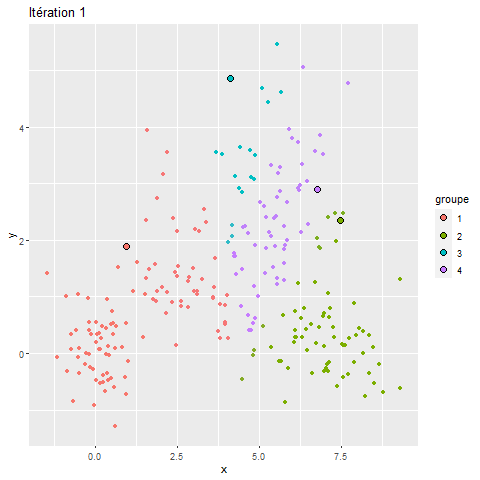
Figure 13.18: Classifications stricte et floue
Nous pouvons constater que, pour ce jeu de données relativement simple, l’algorithme converge très rapidement et que sa solution varie peu au-delà de la troisième itération. Si vous utilisez la version HTLM du livre, la figure 13.18 devrait être animée et illustrer pourquoi le k-means est aussi appelé algorithme de nuées dynamiques.
Centre de groupe et k-means
À nouveau, puisque chaque itération du k-means nécessite de recalculer les centres des groupes formés, des problèmes peuvent être rencontrés avec certains types de distance. C’est pourquoi il est recommandé d’utiliser la distance euclidienne avec le k-means original. Si des distances plus complexes doivent être utilisées, il est préférable d’utiliser la classification ascendante hiérarchique.
13.4.1.2 Choix du nombre optimal de groupes
Comme pour la CAH, le principal enjeu avec le k-means est de déterminer le nombre idéal de groupes pour effectuer la classification. Si ce nombre n’est pas connu à l’avance et qu’aucune forte justification théorique n’existe, il est possible d’utiliser les mêmes techniques que pour la CAH, soit la méthode du coude, l’indicateur de silhouette ou la méthode GAP.
13.4.2 K-médianes
Le k-medians est une variante du k-means. Contrairement au k-means privilégiant la distance euclidienne, le k-medians est à utiliser en priorité avec une distance de Manhattan. En effet, le centre d’un groupe n’est pas déterminé comme la moyenne des variables des observations appartenant à ce groupe (k-means), mais comme la médiane pour chaque variable (k-medians). En dehors de ces deux spécificités, il reprend le fonctionnement décrit plus haut pour le k-means. Il est particulièrement pertinent de l’utiliser quand un jeu de données comprend un très grand nombre de colonnes, car dans ce contexte, la distance euclidienne peine à représenter les différences entre les observations. De plus, l’utilisation de la médiane le rend moins sensible aux valeurs extrêmes.
13.4.3 K-médoïds
Le k-médoïds est également une variante du k-means. Le k-means crée des groupes en cherchant les centres de ces groupes dans l’espace multidimensionnel des données. Ces centres de groupes peuvent très bien ne pas correspondre à un point du jeu de données, au même titre que la moyenne d’une variable ne coïncide que rarement avec une observation réelle de cette variable. Pour le k-médoïds, les groupes sont formés en cherchant les centres de ces groupes parmi les observations du jeu de données. Ainsi, chaque groupe est centré sur une observation réelle, la plus similaire à l’ensemble des observations du groupe.
L’algorithme effectue les opérations suivantes :
- Sélectionner aléatoirement k observations du jeu de données, elles constituent les centres des groupes initiaux.
- Attribuer chaque observation au centre du groupe le plus proche.
- Tant que la nouvelle solution est plus efficace, effectuer les opérations suivantes :
- pour chaque centre m et pour chaque observation o,
- considérer l’inversion de m et o
- si cette permutation est meilleure que les précédentes, la conserver en mémoire
- effectuer la meilleure permutation retenue si elle améliore la classification, sinon l’algorithme prend fin.
Le k-médoïds est moins utilisé que le k-means, mais il est plus performant quand des distances autres que la distance euclidienne sont utilisées ou encore que des valeurs aberrantes/extrêmes sont présentes dans les données.
13.4.4 Mise en oeuvre dans R
Pour cet exemple, nous proposons d’utiliser le jeu de données spatiales LyonIris du package geocmeans. Ce jeu de données spatiales pour l’agglomération lyonnaise (France) comprend dix variables, dont quatre environnementales (EN) et six socioéconomiques (SE), pour les îlots regroupés pour l’information statistique (IRIS) de l’agglomération lyonnaise (tableau 13.7 et figure 12.4). Nous proposons de réaliser une analyse similaire à celle de l’article de Gelb et Apparicio (2021b), soit de classer les IRIS de Lyon selon ces caractéristiques pour déterminer si certains groupes d’IRIS combinent des situations désavantageuses sur les plans sociaux et environnementaux, dans une perspective d’équité environnementale.
Notez ici que la fonction st_drop_geometry provenant du package sf permet de retirer l’information géographique du jeu de données LyonIris pour obtenir un simple dataframe.
| Nom | Intitulé | Type | Moy. | E.-T. | Min. | Max. |
|---|---|---|---|---|---|---|
| Lden | Bruit routier (Lden dB(A)) | EN | 55,6 | 4,9 | 33,9 | 71,7 |
| NO2 | Dioxyde d’azote (ug/m3) | EN | 28,7 | 7,9 | 12,0 | 60,2 |
| PM25 | Particules fines (PM\(_{2,5}\)) | EN | 16,8 | 2,1 | 11,3 | 21,9 |
| VegHautPrt | Canopée (%) | EN | 18,7 | 10,1 | 1,7 | 53,8 |
| Pct0_14 | Moins de 15 ans (%) | SE | 18,5 | 5,7 | 0,0 | 54,0 |
| Pct_65 | 65 ans et plus (%) | SE | 16,2 | 5,9 | 0,0 | 45,1 |
| Pct_Img | Immigrants (%) | SE | 14,5 | 9,1 | 0,0 | 59,8 |
| TxChom1564 | Taux de chômage | SE | 14,8 | 8,1 | 0,0 | 98,8 |
| Pct_brevet | Personnes à faible scolarité (%) | SE | 23,5 | 12,6 | 0,0 | 100,0 |
| NivVieMed | Médiane du niveau de vie (Euros) | SE | 21 804,5 | 4 922,5 | 11 324,0 | 38 707,0 |
13.4.4.1 Préparation des données
La première étape consiste donc à charger les données et à les préparer pour l’analyse. Toutes les variables que nous utilisons sont des variables continues. Cependant, elles ne sont pas exprimées dans la même échelle, nous proposons donc de les standardiser ici en les centrant (moyenne = 0) et en les réduisant (écart-type = 1). Cette opération peut être effectuée simplement dans R en utilisant la fonction scale.
# Chargement des données
library(geocmeans)
library(sf)
data(LyonIris)
# NB : LyonIris est un objet spatial, il faut donc extraire uniquement son DataFrame
X <- st_drop_geometry(LyonIris[c("Lden","NO2","PM25","VegHautPrt","Pct0_14","Pct_65","Pct_Img",
"TxChom1564","Pct_brevet","NivVieMed")])
# Centrage et réduction de chaque colonne du DataFrame
for (col in names(X)){
X[[col]] <- scale(X[[col]], center = TRUE, scale = TRUE)
}13.4.4.2 Choix du nombre de groupes optimal
La seconde étape consiste à déterminer le nombre de groupes optimal. Pour cela, nous comparons les résultats des trois méthodes proposées : la méthode du coude, l’indice de silhouette et la méthode GAP. Pour chaque méthode, nous testons les nombres de groupes de 2 à 10.
13.4.4.2.1 Méthode du coude
Commençons par appliquer la méthode du coude. Nous calculons donc l’inertie expliquée par la classification pour différentes valeurs de k (nombre de groupes) avant de construire la figure 13.19.
ks <- 2:10
## ---- Méthode du coude ---- ##
inertie_exps <- sapply(ks, function(k){
# calcul du kmeans avec k
resultat <- kmeans(X, centers = k)
# calcul de l'inertie expliquée (1 - inertie intragroupe / inertie totale)
inertie_exp <- 1-(sum(resultat$withinss) / resultat$totss)
return(inertie_exp)
})
df <- data.frame(
k = ks,
inertie_exp = inertie_exps
)
ggplot(df) +
geom_line(aes(x = k, y = inertie_exp)) +
geom_point(aes(x = k, y = inertie_exp), color = "red") +
labs(x = "nombre de groupes", y = "inertie expliquée (%)")
Figure 13.19: Inertie expliquée pour différents nombres de groupes pour le k-means
Dans l’article original, quatre groupes avaient été retenus. Nous pouvons constater ici qu’un coude fort se situe à k = 3 et qu’au-delà de cette limite, l’ajout d’un groupe supplémentaire contribue à expliquer une plus petite partie de l’inertie supplémentaire comparativement au précédent.
13.4.4.2.2 Indice de silhouette
Poursuivons avec l’indice de silhouette calculé de nouveau avec des valeurs de k allant de 2 à 10. Notez que nous devons au préalable créer une matrice de distances entre les observations du jeu de données pour construire notre indice de silhouette. Puisque nous utilisons l’algorithme k-means, nous utilisons la distance euclidienne.
ks <- 2:10
# calcul d'une matrice de distance euclidienne entre les observations
dist_mat <- dist(X, method = "euclidean")
## ---- indice de silhouette ---- ##
values <- sapply(ks, function(k){
resultat <- kmeans(X,centers = k)
groupes <- resultat$cluster
# calcul des valeurs de silhouette
sil <- silhouette(groupes, dist = dist_mat)
# extraction de l'indice global (moyenne des moyennes)
idx <- mean(summary(sil)$clus.avg.widths)
return(idx)
})
df <- data.frame(
k = ks,
silhouette = values
)
ggplot(df) +
geom_line(aes(x = k, y = silhouette)) +
geom_point(aes(x = k, y = silhouette), color = "red") +
labs(x = "nombre de groupes", y = "Indice de silhouette")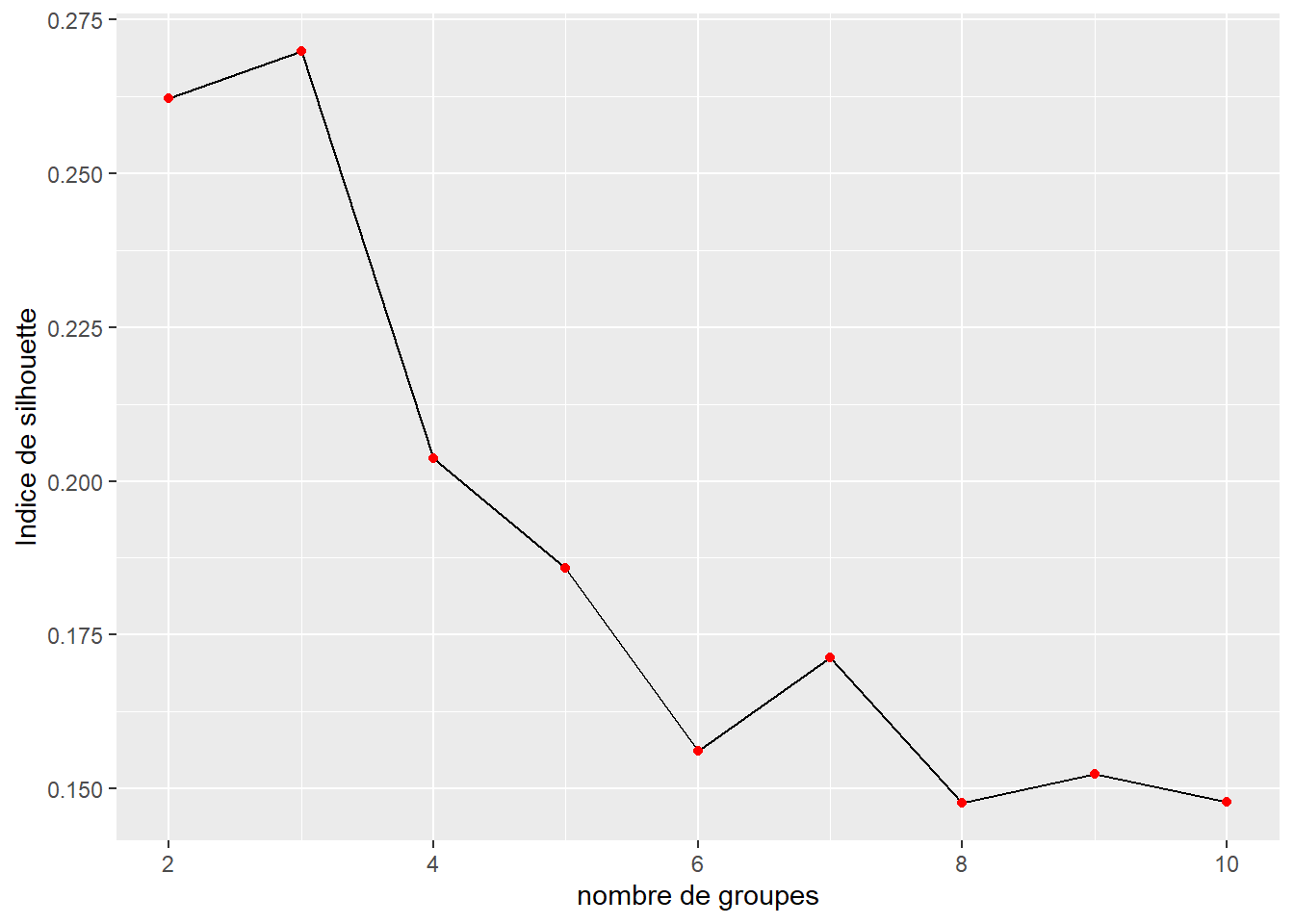
Figure 13.20: Indice de silhouette pour différents nombres de groupes pour le k-means
À nouveau, la figure 13.20 indique que le nombre de groupes optimal est trois selon l’indice de silhouette.
13.4.4.2.3 Méthode GAP
Pour appliquer la méthode GAP, nous proposons d’utiliser la fonction clusGap du package NbClust. Pour l’utiliser, il est nécessaire de définir une fonction renvoyant pour le nombre de groupes k et le jeu de données x une liste comprenant un vecteur attribuant chaque observation à chaque groupe. Il est possible de considérer ce type de fonction comme un « adaptateur ».
library(NbClust)
# définition de la fonction adaptateur
adaptor <- function(x,k){
clust <- kmeans(x,k)
return(list(
"cluster" = clust$cluster
))
}
# calcul de la méthode GAP
vals <- clusGap(X, adaptor, K.max = 10, verbose = FALSE)
tab <- data.frame(vals$Tab)
tab$k <- 1:nrow(tab)
# détermination des valeurs de k retenues par la méthode (1ere et 2e)
is_valid <- sapply(2:nrow(tab), function(i){
tab[i-1,"gap"] >= (tab[i,"gap"] - tab[i,"SE.sim"])
})
valids <- subset(tab,is_valid)[1,]
valids2 <- subset(tab,is_valid)[2,]
# réalisation du graphique
ggplot(tab) +
geom_line(aes(x = k, y = gap)) +
geom_segment(x = valids$k, xend = valids$k, y = min(tab$gap), yend = valids$gap,
linetype = "dashed") +
geom_segment(x = valids2$k, xend = valids2$k, y = min(tab$gap), yend = valids2$gap,
linetype = "dashed") +
geom_point(aes(x = k, y = gap), color = 'red') +
scale_x_continuous(breaks = 1:10) +
labs(x = "nombre de groupes", y = "GAP")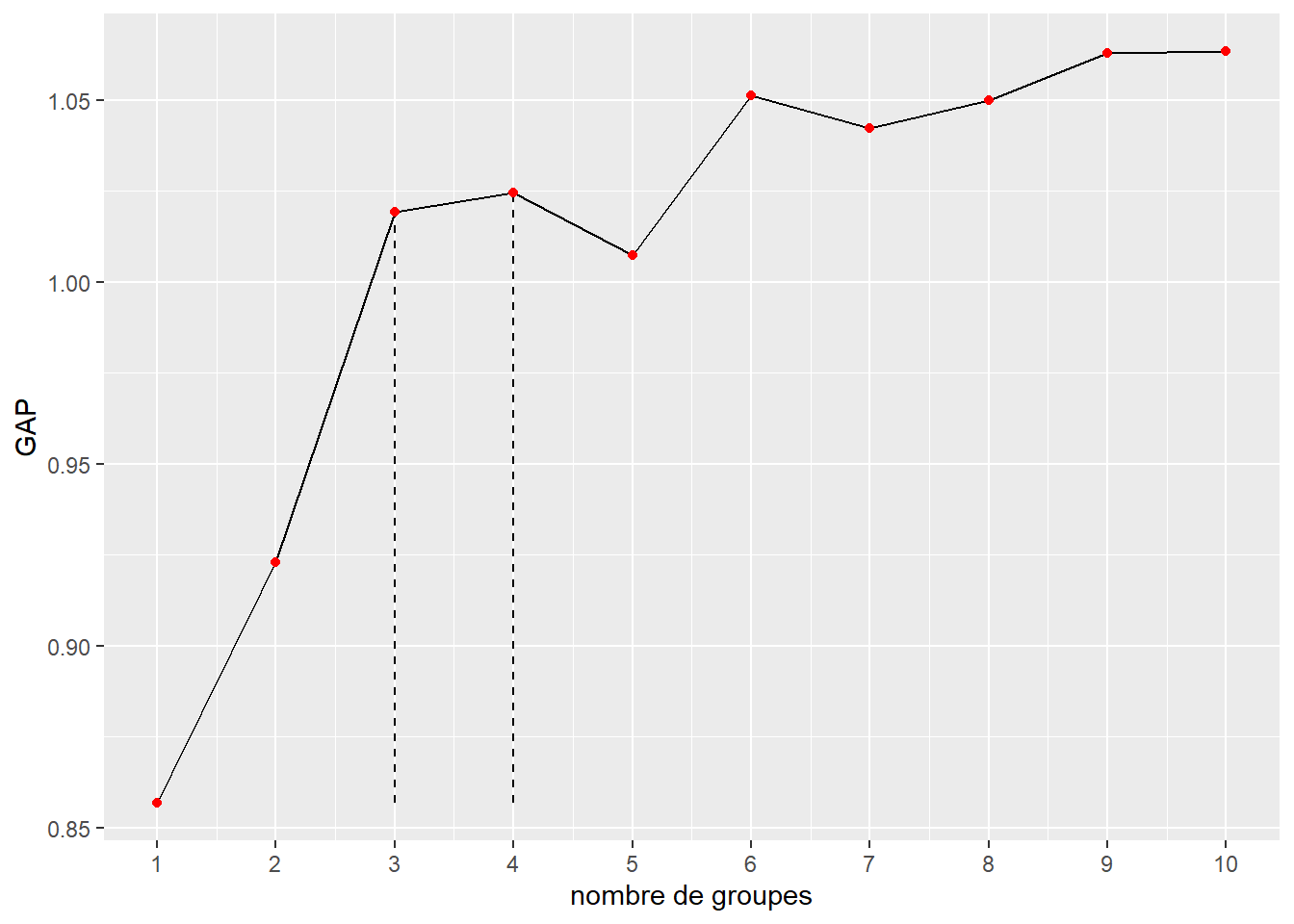
Figure 13.21: Méthode GAP pour différents nombres de groupes pour le k-means
La figure 13.21 indique également que le nombre de groupes à retenir est trois. Nous retenons cependant quatre groupes pour pouvoir plus facilement comparer nos résultats avec ceux de l’article original.
13.4.4.3 Application l’algorithme du k-means
Maintenant que nous avons choisi le nombre de groupes à former, nous pouvons simplement appliquer la fonction kmeans présente de base dans R.
set.seed(145)
resultats <- kmeans(X, centers = 4)13.4.4.4 Interprétation des résultats
Une fois les groupes obtenus, l’étape la plus importante est de parvenir à interpréter ces groupes. Pour cela, il est nécessaire de les explorer en profondeur au travers des variables utilisées pour les constituer. Dans notre cas, le jeu de données LyonIris est spatialisé, nous pouvons donc commencer par cartographier les groupes.
library(tmap)
LyonIris$groupes <- paste("groupe", resultats$cluster, sep = " ")
tm_shape(LyonIris) +
tm_polygons(col = "groupes", palette =
c("#EFBE89", "#4A6A9F", "#7DB47C", "#FAF29C"),lty = 1, lwd = 0.1)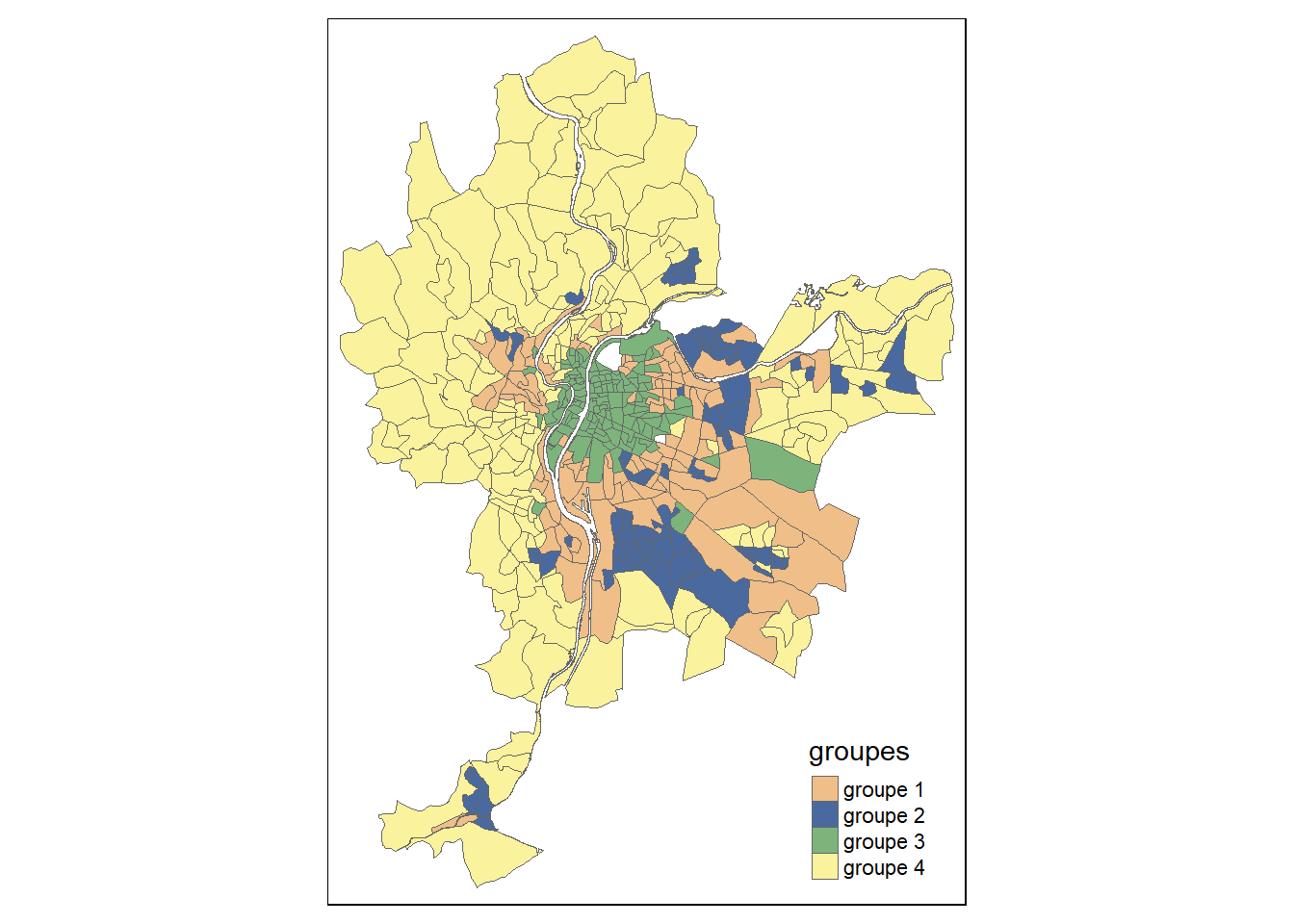
Figure 13.22: Cartographie des groupes obtenus avec la méthode du k-means
Il est ainsi possible de constater que le groupe 3 forme un ensemble assez compact d’IRIS au centre de Lyon. Le groupe 4 correspond quant à lui à des IRIS situés en périphérie plutôt éloignée, essentiellement à l’ouest. Le groupe 1 correspond à une périphérie proche du groupe 2 et apparaît comme un ensemble d’enclaves dispersées.
Pour distinguer rapidement les profils des différents groupes, il est possible d’utiliser un graphique en radar. La construction d’un tel graphique peut être un peu fastidieuse dans R, cependant le package geocmeans propose une fonction assez pratique : spiderPlots.
library(geocmeans)
# création d'une matrice d'appartenance binaire des groupes
matrice_gp <- fastDummies::dummy_cols(resultats$cluster, remove_selected_columns = TRUE)
# réalisation du graphique
par(mfrow=c(3,2), mai = c(0.1,0.1,0.1,0.1))
plots <- spiderPlots(X, matrice_gp,
chartcolors = c("#EFBE89", "#4A6A9F", "#7DB47C", "#FAF29C"))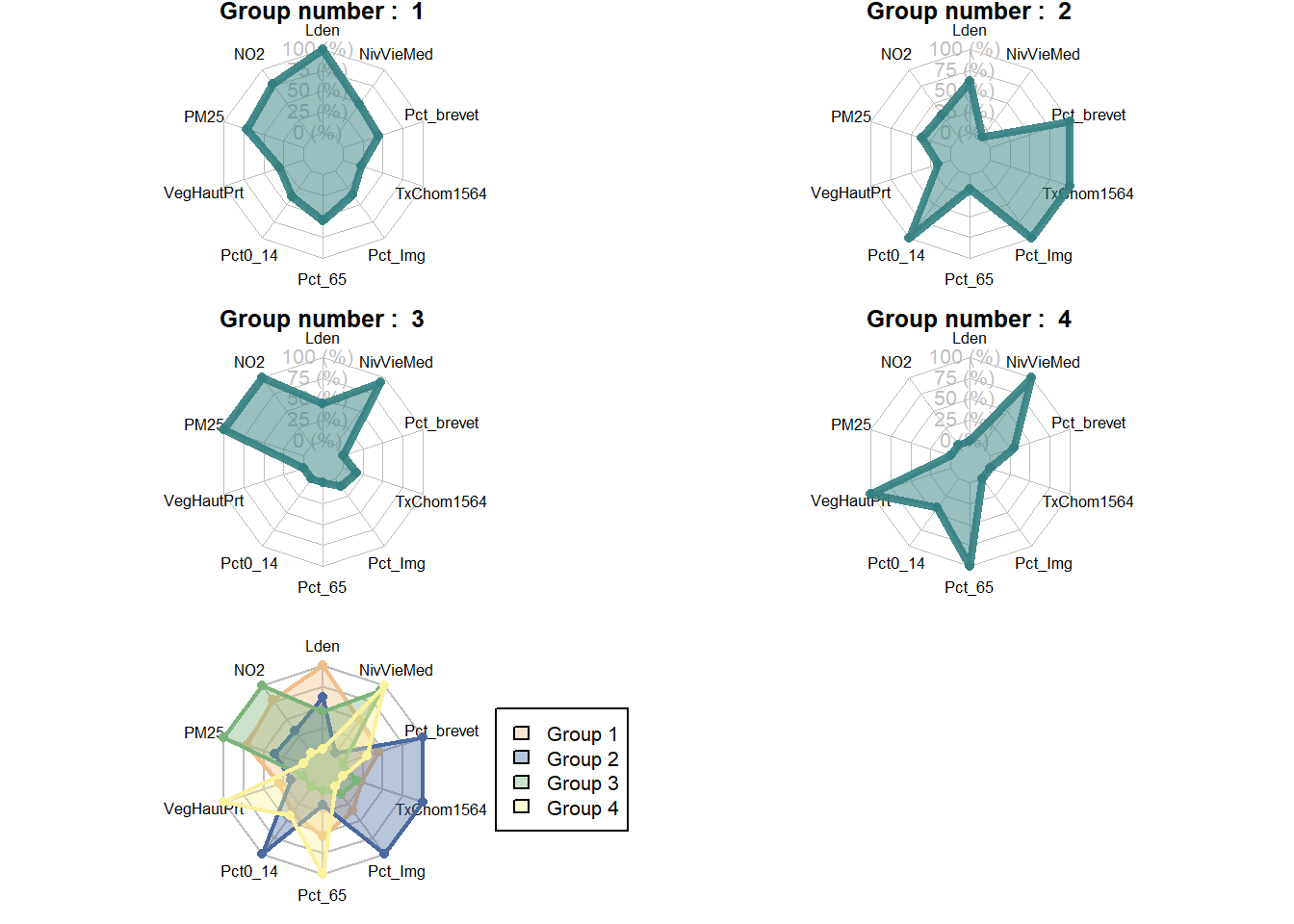
Figure 13.23: Graphiques en radar pour les groupes issus du k-means
Il est ainsi possible de constater, à la figure 13.23, que le groupe 3 est caractérisé par un niveau de vie élevé, mais par des niveaux de concentration de pollution atmosphérique plus élevés également. Le groupe 4 en revanche est caractérisé par un important couvert végétal, un niveau de vie médian élevé et une plus forte proportion de personnes de plus de 65 ans. Le groupe 1 est quant à lui marqué par des niveaux sonores plus élevés. Enfin, le groupe 2 se caractérise par une plus grande proportion de population ayant obtenu comme diplôme le plus élevé le brevet des collèges, d’immigrants, de jeunes de moins de 15 ans et un taux de chômage plus élevé.
Notez que ces graphiques nous permettent rapidement de nous faire une idée des caractéristiques des groupes, mais uniquement sur une échelle relative. En effet, ils ne nous indiquent à aucun moment la taille des écarts entre les groupes. Pour cela, il est nécessaire de réaliser des graphiques en violon pour chaque variable. Pour ce type de graphique, il est préférable d’utiliser les données originales non transformées pour pouvoir mieux appréhender si les différences entre les groupes sont importantes ou négligeables.
X2 <- st_drop_geometry(LyonIris[c("Lden","NO2","PM25","VegHautPrt","Pct0_14",
"Pct_65","Pct_Img","TxChom1564","Pct_brevet",
"NivVieMed")])
plots <- violinPlots(X2, as.character(resultats$cluster))
ggarrange(plotlist = plots, ncol = 2, nrow = 5)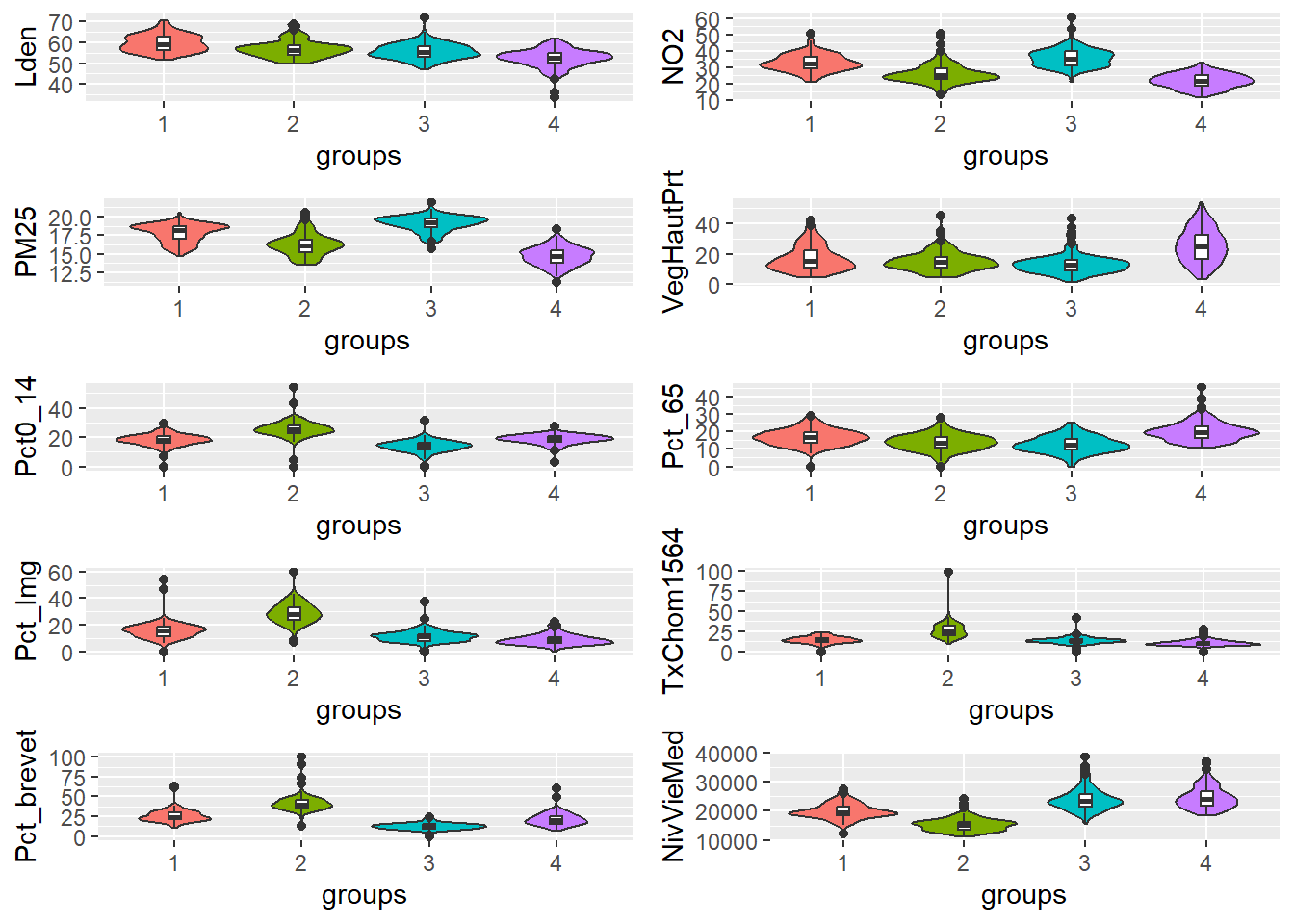
Figure 13.24: Graphiques en violon pour les groupes issus du k-means
Il est également recommandé de calculer des statistiques descriptives par groupe et de les rapporter dans un tableau.
# obtention d'un tableau par groupe
tableaux <- summarizeClusters(X2, matrice_gp, dec = 1, silent = TRUE)
# concaténation des tableaux
tableau_tot <- do.call(rbind, tableaux)| Lden | NO2 | PM25 | VegHautPrt | Pct014 | Pct65 | PctImg | TxChom1564 | Pctbrevet | NivVieMed | |
|---|---|---|---|---|---|---|---|---|---|---|
| groupe 1 | ||||||||||
| Q5 | 53,8 | 25,2 | 15,6 | 6,6 | 12,4 | 10,0 | 8,1 | 7,6 | 17,4 | 15 822,7 |
| Q10 | 54,5 | 26,4 | 15,9 | 8,0 | 13,9 | 11,4 | 9,2 | 9,8 | 18,1 | 16 976,0 |
| Q25 | 56,3 | 29,3 | 17,0 | 11,0 | 16,3 | 13,6 | 11,8 | 11,5 | 20,8 | 18 454,0 |
| Q50 | 58,9 | 32,3 | 18,2 | 15,3 | 18,3 | 16,6 | 15,9 | 13,7 | 24,1 | 19 559,0 |
| Q75 | 62,5 | 36,5 | 18,7 | 22,3 | 20,5 | 19,5 | 18,6 | 16,9 | 30,0 | 21 575,2 |
| Q90 | 64,7 | 39,3 | 19,0 | 30,3 | 22,7 | 22,8 | 21,1 | 19,8 | 33,0 | 23 544,7 |
| Q95 | 66,7 | 40,7 | 19,3 | 35,6 | 24,9 | 25,1 | 23,0 | 21,9 | 37,7 | 24 765,7 |
| Mean | 59,6 | 32,7 | 17,8 | 17,2 | 18,2 | 16,7 | 15,7 | 14,1 | 25,5 | 19 948,0 |
| Std | 4,2 | 5,2 | 1,2 | 8,5 | 4,0 | 4,7 | 6,5 | 4,3 | 7,6 | 2 637,2 |
| groupe 2 | ||||||||||
| Q5 | 50,8 | 19,3 | 13,9 | 6,1 | 18,3 | 6,4 | 17,7 | 16,5 | 30,5 | 12 323,5 |
| Q10 | 52,0 | 20,2 | 14,3 | 7,8 | 20,0 | 8,7 | 20,2 | 16,8 | 32,9 | 12 747,0 |
| Q25 | 53,9 | 23,0 | 15,3 | 11,2 | 22,8 | 10,7 | 23,5 | 19,6 | 36,2 | 13 530,5 |
| Q50 | 56,4 | 25,1 | 16,2 | 14,5 | 25,2 | 13,6 | 28,0 | 24,5 | 39,9 | 15 340,0 |
| Q75 | 58,4 | 29,4 | 17,0 | 18,1 | 27,8 | 16,9 | 33,5 | 32,5 | 46,0 | 16 342,0 |
| Q90 | 63,1 | 33,7 | 18,5 | 24,4 | 31,3 | 20,2 | 38,2 | 36,3 | 50,2 | 18 363,9 |
| Q95 | 64,9 | 39,0 | 19,1 | 28,1 | 32,8 | 21,4 | 41,1 | 38,0 | 60,2 | 20 128,6 |
| Mean | 56,8 | 26,3 | 16,2 | 15,4 | 25,4 | 13,8 | 28,5 | 26,6 | 42,0 | 15 401,4 |
| Std | 4,1 | 6,3 | 1,5 | 6,8 | 6,2 | 4,8 | 8,0 | 10,5 | 11,3 | 2 340,4 |
| groupe 3 | ||||||||||
| Q5 | 50,2 | 28,3 | 17,0 | 5,0 | 6,8 | 5,2 | 5,8 | 7,7 | 6,7 | 19 029,9 |
| Q10 | 51,2 | 29,5 | 17,6 | 6,6 | 9,5 | 7,2 | 6,7 | 8,5 | 7,7 | 19 546,4 |
| Q25 | 53,2 | 31,3 | 18,6 | 9,2 | 11,4 | 9,5 | 7,9 | 11,0 | 9,5 | 21 652,0 |
| Q50 | 55,2 | 35,4 | 19,3 | 12,6 | 14,1 | 12,4 | 11,0 | 12,9 | 12,0 | 23 342,0 |
| Q75 | 58,0 | 39,6 | 19,8 | 16,0 | 16,2 | 16,0 | 13,1 | 15,1 | 14,8 | 25 954,1 |
| Q90 | 60,0 | 43,0 | 20,1 | 21,0 | 18,2 | 18,9 | 16,3 | 18,0 | 16,6 | 28 951,0 |
| Q95 | 61,2 | 44,4 | 20,4 | 29,3 | 19,5 | 20,9 | 17,7 | 19,3 | 19,1 | 31 922,5 |
| Mean | 55,6 | 35,8 | 19,0 | 13,6 | 13,8 | 12,6 | 11,1 | 13,1 | 12,1 | 23 999,7 |
| Std | 3,7 | 5,6 | 1,0 | 6,8 | 4,2 | 4,7 | 4,6 | 4,4 | 4,0 | 3 870,3 |
| groupe 4 | ||||||||||
| Q5 | 44,9 | 14,7 | 12,7 | 8,2 | 13,1 | 12,7 | 3,8 | 6,7 | 10,8 | 19 496,0 |
| Q10 | 46,6 | 15,7 | 13,0 | 11,8 | 14,9 | 13,5 | 4,4 | 7,0 | 12,4 | 20 257,0 |
| Q25 | 50,3 | 19,0 | 13,8 | 16,7 | 17,1 | 16,1 | 6,0 | 8,0 | 15,7 | 21 963,0 |
| Q50 | 52,6 | 22,0 | 14,7 | 24,9 | 18,9 | 19,3 | 8,1 | 9,8 | 20,0 | 24 109,8 |
| Q75 | 54,9 | 25,2 | 15,5 | 32,6 | 20,8 | 22,8 | 10,9 | 12,0 | 25,6 | 26 698,0 |
| Q90 | 57,7 | 27,5 | 16,3 | 41,2 | 22,3 | 27,4 | 14,5 | 14,7 | 30,6 | 29 947,0 |
| Q95 | 59,1 | 28,7 | 16,8 | 43,6 | 22,7 | 29,7 | 18,1 | 16,6 | 33,1 | 32 386,5 |
| Mean | 52,3 | 21,8 | 14,7 | 25,5 | 18,6 | 20,1 | 8,8 | 10,4 | 21,1 | 24 761,6 |
| Std | 4,3 | 4,4 | 1,2 | 11,0 | 3,1 | 5,6 | 4,2 | 3,4 | 7,6 | 4 008,7 |
Les constats que nous avons faits précédemment sont confirmés par la figure 13.24 et le tableau 13.8. Nous retrouvons ici les groupes originaux décrits dans l’article de Gelb et Apparicio (2021b) :
- Groupe 1 : les espaces interstitiels, formant une périphérie proche du centre et relativement hétérogène sur les variables étudiées, mais caractérisée par des niveaux de bruit importants.
- Groupe 2 : les banlieues jeunes et défavorisées, avec des niveaux d’exposition aux pollutions atmosphérique et sonore relativement élevés comparativement à l’ensemble de la région.
- Groupe 3 : les quartiers centraux aisés, mais marqués par les plus hauts niveaux de pollution atmosphérique.
- Groupe 4 : les communes rurales, aisées et vieillissantes.
Interprétation interactive
Si, comme dans notre exemple, vos données comportent une dimension spatiale, le package geocmeans propose une fonction intéressante appelée sp_clust_explorer démarrant une application permettant d’explorer les résultats de votre classification. Le seul enjeu est de créer un objet de la classe FCMres. Voici un court exemple :
# création d'une matrice binaire d'appartenance
kmeans_mat <- dummy_cols(resultats$cluster, remove_selected_columns = TRUE)
# extraction des centres de notre classification
centres <- resultats$centers
# création de l'objet FCMres
kmeansres <- FCMres(list(
"Centers" = centres,
"Belongings" = kmeans_mat,
"Data" = X2,
"m" = 1,
"algo" = "kmeans"
))
# démarrage de l'application shiny
sp_clust_explorer(object = kmeansres, spatial = LyonIris)13.4.4.5 K-médianes et K-médoides
Nous présentons simplement ici comment effectuer la même analyse en utilisant les variantes du k-means, soit le k-medians et le k-mediods.
Il existe relativement peu d’implémentation du k-medians dans R, nous optons donc ici pour la fonction kGmedian du package Gmedian. Pour le k-mediods, nous avons retenu la fonction pam du package cluster.
library(Gmedian)
k_median_res <- kGmedian(X, 4)
library(cluster)
k_mediods_res <- pam(X,4)Juste pour le plaisir des yeux, nous pouvons cartographier les trois classifications obtenues en nous assurant au préalable de faire coïncider les groupes les plus similaires de nos trois classifications.
matrice_gp_kmeans <- dummy_cols(resultats$cluster,
remove_selected_columns = TRUE)
matrice_gp_kmedians <- dummy_cols(as.vector(k_median_res$cluster),
remove_selected_columns = TRUE)
matrice_gp_kmedioids <- dummy_cols(k_mediods_res$cluster,
remove_selected_columns = TRUE)
# Appariement des groupes du k-medians avec ceux du kmeans
matrice_gp_kmedians <- geocmeans::groups_matching(as.matrix(matrice_gp_kmeans),
as.matrix(matrice_gp_kmedians))
# Appariement des groupes du k-medioids avec ceux du kmeans
matrice_gp_kmedioids <- geocmeans::groups_matching(as.matrix(matrice_gp_kmeans),
as.matrix(matrice_gp_kmedioids))
# ajouts des colonnes nécessaires à LyonIris
colnames(matrice_gp_kmeans) <- paste0("groupe_", 1:4)
colnames(matrice_gp_kmedians) <- paste0("groupe_", 1:4)
colnames(matrice_gp_kmedioids) <- paste0("groupe_", 1:4)
LyonIris$kmeans <- colnames(matrice_gp_kmeans)[max.col(matrice_gp_kmeans)]
LyonIris$kmedians <- colnames(matrice_gp_kmedians)[max.col(matrice_gp_kmedians)]
LyonIris$kmedioids <- colnames(matrice_gp_kmedioids)[max.col(matrice_gp_kmedioids)]
# construction de la figure
couleurs <- c("#EFBE89", "#4A6A9F", "#7DB47C", "#FAF29C")
map1 <- tm_shape(LyonIris) +
tm_polygons(col = "kmeans",palette = couleurs,lty = 1, lwd = 0.1)
map2 <- tm_shape(LyonIris) +
tm_polygons(col = "kmedians",palette = couleurs,lty = 1, lwd = 0.1)
map3 <- tm_shape(LyonIris) +
tm_polygons(col = "kmedioids",palette = couleurs,lty = 1, lwd = 0.1)
tmap_arrange(map1, map2, map3,
ncol = 2, nrow = 2)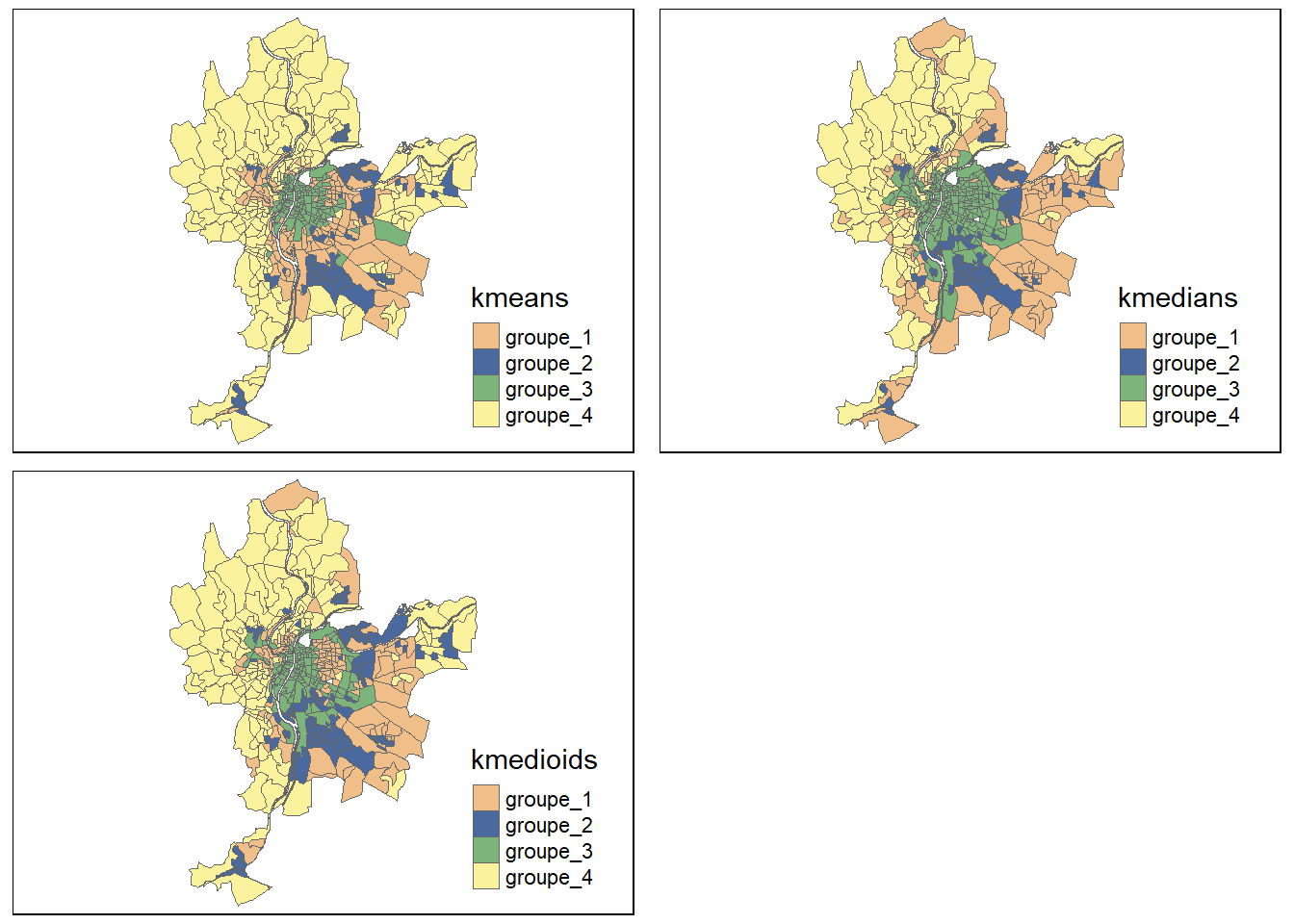
Figure 13.25: Comparaison géographique des résultats obtenus pour le k-means, le k-medians et le k-medoids
Les trois cartes sont très similaires (figure 13.25), ce qui signifie que les trois algorithmes tendent à attribuer les observations aux mêmes groupes. Cependant, nous observons des différences, notamment au nord avec des observations alternant entre les groupes 2 et 3 selon la méthode employée. Cela peut notamment signifier que ces observations sont « indécises », qu’il est difficile de les attribuer définitivement à une catégorie en particulier. Pour prendre en compte cette forme d’incertitude, il est possible d’opter pour des méthodes de classification en logique floue.
13.4.5 Extensions en logique floue : c-means, c-medoids
Comme nous l’avons mentionné en introduction de cette section, les méthodes de classification floues ont pour objectif d’évaluer le degré d’appartenance de chaque observation à chaque groupe plutôt que d’attribuer chaque observation à un seul groupe. Il est ainsi possible de repérer des observations incertaines, à cheval entre plusieurs groupes. Nous présentons ici deux algorithmes appartenant à cette famille : le c-means et le c-medoids. Il s’agit dans les deux cas d’extensions des k-means et k-medoids vus précédemment.
Pour ces deux méthodes, comme pour le k-means, le nombre de groupes k doit être spécifié. Elles comprennent cependant un paramètre supplémentaire : m, appelé paramètre de floutage qui contrôle à quel point le résultat obtenu sera flou ou strict. Une valeur de 1 produit une classification stricte (chaque observation appartient à un seul groupe) et une valeur plus grande conduit à des classifications de plus en plus floues, jusqu’à ce que chaque observation appartienne à un degré identique à chacun des groupes. Il est recommandé de sélectionner m en même temps que k, car ces deux valeurs influencent simultanément la qualité de la classification. La meilleure approche consiste à tester un ensemble de combinaisons de m et de k et à comparer les valeurs obtenues pour différents indicateurs de qualité de classification floue. Parmi ces indicateurs, il est notamment recommandé d’utiliser le pourcentage de l’inertie expliquée, l’indice de silhouette pour classification floue, l’indice de Xie et Beni (1991), et de Fukuyama et Sugeno (Fukuyama 1989).
13.4.5.1 Mise en oeuvre du c-means dans R
Le package fclust comprend un très grand nombre de méthodes pour effectuer des classifications floues, nous l’utilisons donc en priorité ici en combinaison avec des fonctions d’interprétation du package geocmeans.
13.4.5.1.1 Préparation des données
Comme pour le k-means, cette méthode nécessite de disposer d’un jeu de données ne comprenant que des variables quantitatives dans la même échelle. Nous commençons donc à nouveau par standardiser nos données. Pour varier les plaisirs, nous optons cette fois-ci pour une transformation des variables dans une échelle allant de 0 à 100.
library(fclust)
data(LyonIris)
# NB : LyonIris est un objet spatial, il faut donc extraire uniquement son DataFrame
X <- st_drop_geometry(LyonIris[c("Lden","NO2","PM25","VegHautPrt","Pct0_14",
"Pct_65","Pct_Img",
"TxChom1564","Pct_brevet","NivVieMed")])
# changement d'échelle des données (0 à 100)
to_0_100 <- function(x){
return((x-min(x)) / (max(x) - min(x)) * 100)
}
for (col in names(X)){
X[[col]] <- to_0_100(X[[col]])
}13.4.5.1.2 Sélection de k et de m
La seconde étape consiste à sélectionner les valeurs optimales pour k et m. Nous testons ici toutes les valeurs de k de 2 à 7, et les valeurs de m de 1,5 à 2,5 (avec des écarts de 0,1).
library(e1071)
set.seed(123)
ms <- seq(1.5,2.5,by = 0.1)
ks <- 2:7
# calcul de toutes les combinaisons
combinaisons <- expand.grid(ms,ks)
eval_indices <- c("Explained.inertia", "Silhouette.index", "FukuyamaSugeno.index")
values <- apply(combinaisons, MARGIN = 1, FUN = function(row){
m <- row[[1]]
k <- row[[2]]
resultats <- FKM(X, k, m)
idx <- geocmeans::calcqualityIndexes(as.matrix(X),
as.matrix(resultats$U),
m = m,
indices = eval_indices)
return(c(k,m,unlist(idx)))
})
df_scores <- data.frame(t(values))
names(df_scores) <- c("k", "m", "inertie", "silhouette", "FukuyamaSugeno")
# changer l'échelle de l'indice pour un graphique plus joli
df_scores$FukuyamaSugeno <- round(df_scores$FukuyamaSugeno/10000,2)
# création de trois figures pour représenter les trois indicateurs
library(viridis)
plot1 <- ggplot(df_scores) +
geom_raster(aes(x = k, y = m, fill = inertie)) +
scale_fill_viridis() +
scale_x_continuous(breaks = c(2,3,4,5,6,7)) +
coord_fixed(ratio=4) +
guides(fill = guide_colourbar(barwidth = 5, barheight = 0.5)) +
labs(fill = "Inertie expliquée") +
theme(legend.position = "bottom", legend.box = "horizontal",
legend.title = element_text( size=9), legend.text=element_text(size=8))
plot2 <- ggplot(df_scores) +
geom_raster(aes(x = k, y = m, fill = silhouette)) +
scale_fill_viridis() +
scale_x_continuous(breaks = c(2,3,4,5,6,7)) +
coord_fixed(ratio=4) +
guides(fill = guide_colourbar(barwidth = 5, barheight = 0.5)) +
labs(fill = "Indice de silhouette") +
theme(legend.position = "bottom", legend.box = "horizontal",
legend.title = element_text( size=9), legend.text=element_text(size=8))
plot3 <- ggplot(df_scores) +
geom_raster(aes(x = k, y = m, fill = FukuyamaSugeno)) +
scale_fill_viridis() +
scale_x_continuous(breaks = c(2,3,4,5,6,7)) +
coord_fixed(ratio=4) +
guides(fill = guide_colourbar(barwidth = 5, barheight = 0.5)) +
labs(fill = "Indice de Fukuyama et Sugeno") +
theme(legend.position = "bottom", legend.box = "horizontal",
legend.title = element_text( size=9), legend.text=element_text(size=8))
ggarrange(plot1, plot2, plot3, ncol = 2, nrow = 2)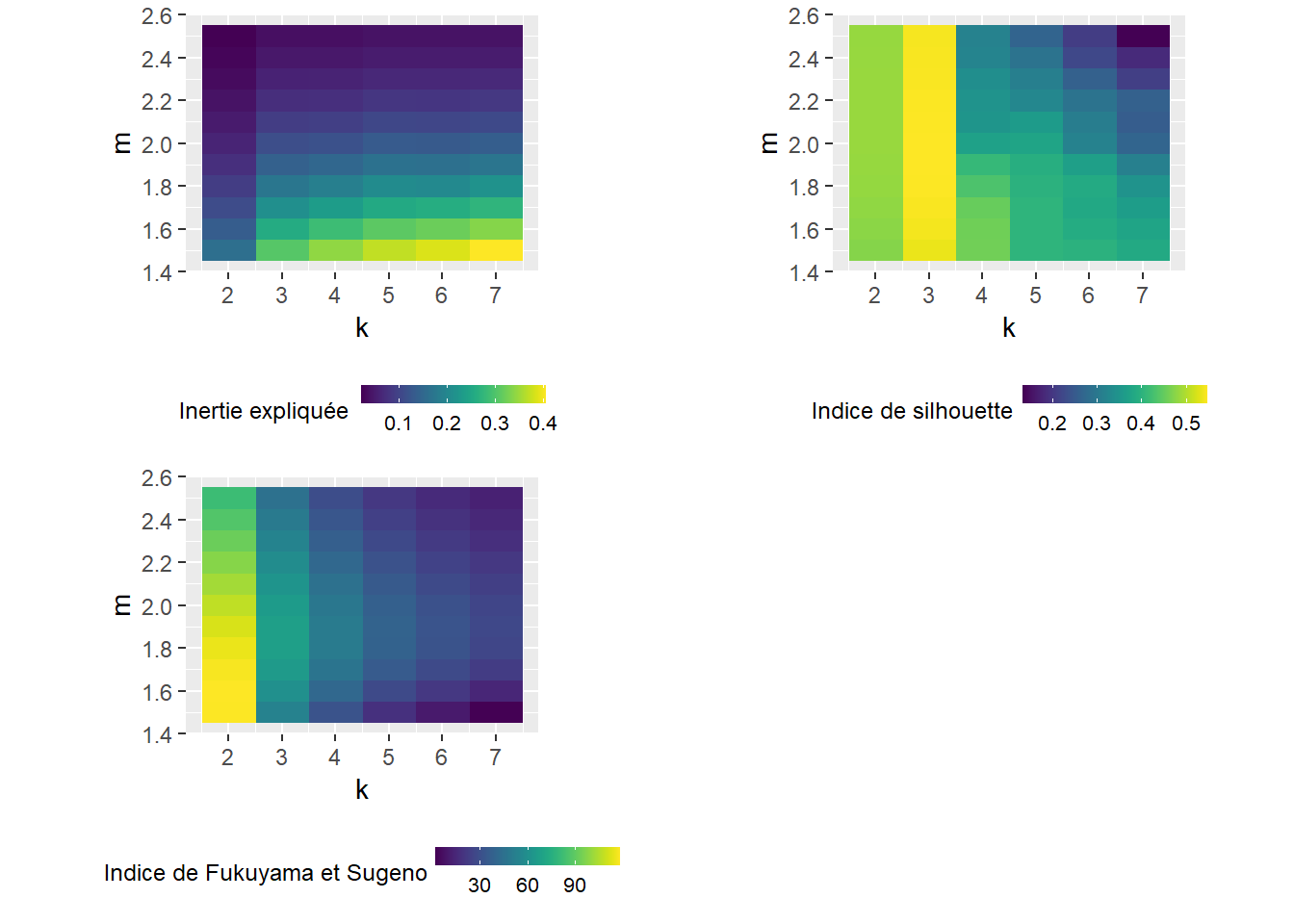
Figure 13.26: Sélection des paramètres k et m pour l’algorithme c-means
Les trois graphiques à la figure 13.26 semblent indiquer des solutions différentes. Sans surprise, augmenter le niveau de flou (m) réduit l’inertie expliquée, alors qu’augmenter le nombre de groupes (k) augmente l’inertie expliquée. L’indice de silhouette indique assez clairement que trois groupes serait le meilleur choix, suivi par deux ou quatre groupes, si m est inférieur à 1,8. Cependant, ne retenir que trois groupes ne permet d’expliquer que 30% de l’inertie. Afin de nous rapprocher des résultats de l’article original (Gelb et Apparicio 2021b), nous retenons m = 1,5 et k = 4.
13.4.5.1.3 Application l’algorithme c-means
Avec k et m définis, il ne reste plus qu’à appliquer l’algorithme à nos observations.
set.seed(123)
cmeans_resultats <- FKM(X, 4, 1.5)L’objet obtenu cmeans_resultats contient les résultats de la classification. Plus spécifiquement, cmeans_resultats$U est la matrice d’appartenance, soit une matrice de taille n x k, dont chaque case \(U_{ij}\) indique la probabilité pour l’observation i d’appartenir au groupe j. cmeans_resultats$H contient le centre des groupes, et cmeans_resultats$Clus, le groupe auquel chaque observation à le plus de chances d’appartenir. Pour comparer plus facilement nos résultats avec ceux du k-means, nous pouvons changer l’ordre des groupes obtenus pour les faire coïncider avec les groupes les plus similaires obtenus avec la méthode k-means.
# changeons l'ordre des groupes
U <- cmeans_resultats$U
U2 <- geocmeans::groups_matching(as.matrix(matrice_gp_kmeans), as.matrix(U))
# mais aussi du centre des classes
idx <- as.integer(gsub("Clus ","",colnames(U2), fixed = TRUE))
H2 <- cmeans_resultats$H[idx,]
# et recalcul du groupe le plus probable
Clus2 <- data.frame(
"Cluster" = (1:4)[max.col(U2,ties.method="first")],
"Membership degree" = apply(U2, MARGIN = 1, max)
)
colnames(U2) <- paste("Clus",1:4, sep = " ")
rownames(H2) <- paste("Clus",1:4, sep = " ")
cmeans_resultats$U <- U2
cmeans_resultats$H <- H2
cmeans_resultats$Clus <- Clus213.4.5.1.4 Interprétation des résultats
Globalement, les approches pour interpréter les résultats issus d’une classification obtenue par c-means sont les mêmes que pour une classification obtenue par k-means.
Commençons donc par créer plusieurs cartes des probabilités d’appartenir aux différents groupes.
maps <- mapClusters(LyonIris, cmeans_resultats$U)
tmap_arrange(maps$ProbaMaps, ncol = 2, nrow = 2)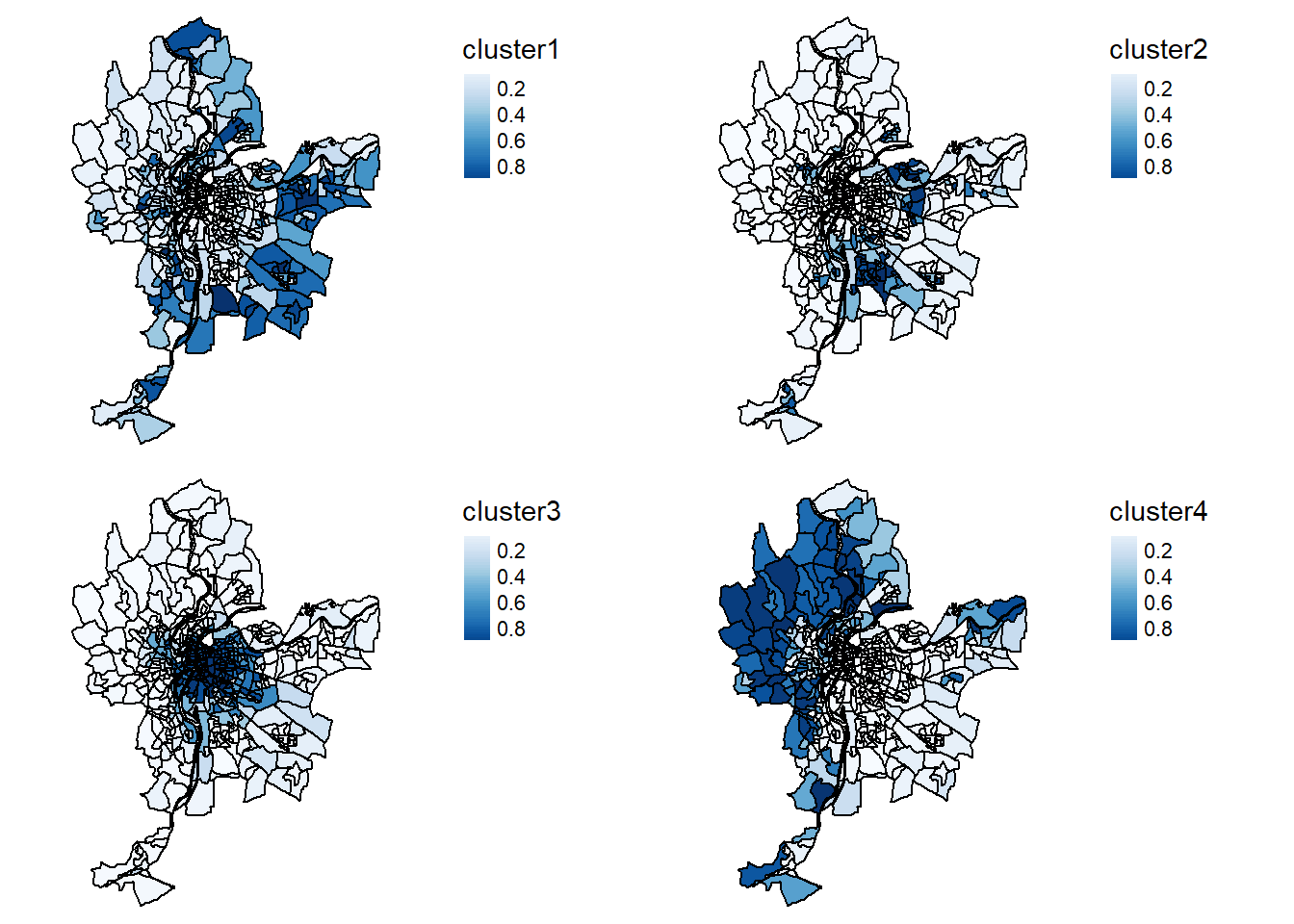
Figure 13.27: Cartographie des probabilités d’appartenir aux quatre groupes identifiés par l’algorithme c-means
Sur les cartes de la figure 13.27, l’intensité de bleu correspond à la probabilité pour chaque IRIS d’appartenir aux différents groupes. Nous retrouvons les principales structures spatiales que nous avons identifiées avec le k-means; cependant, nous pouvons à présent constater que le groupe 1 est bien plus incertain que les autres. Nous pouvons une fois encore générer un graphique en radar pour comparer les profils des quatre groupes.
par(mfrow=c(3,2), mai = c(0.1,0.1,0.1,0.1))
spiderPlots(X, cmeans_resultats$U,
chartcolors = c("#EFBE89", "#4A6A9F", "#7DB47C", "#FAF29C"))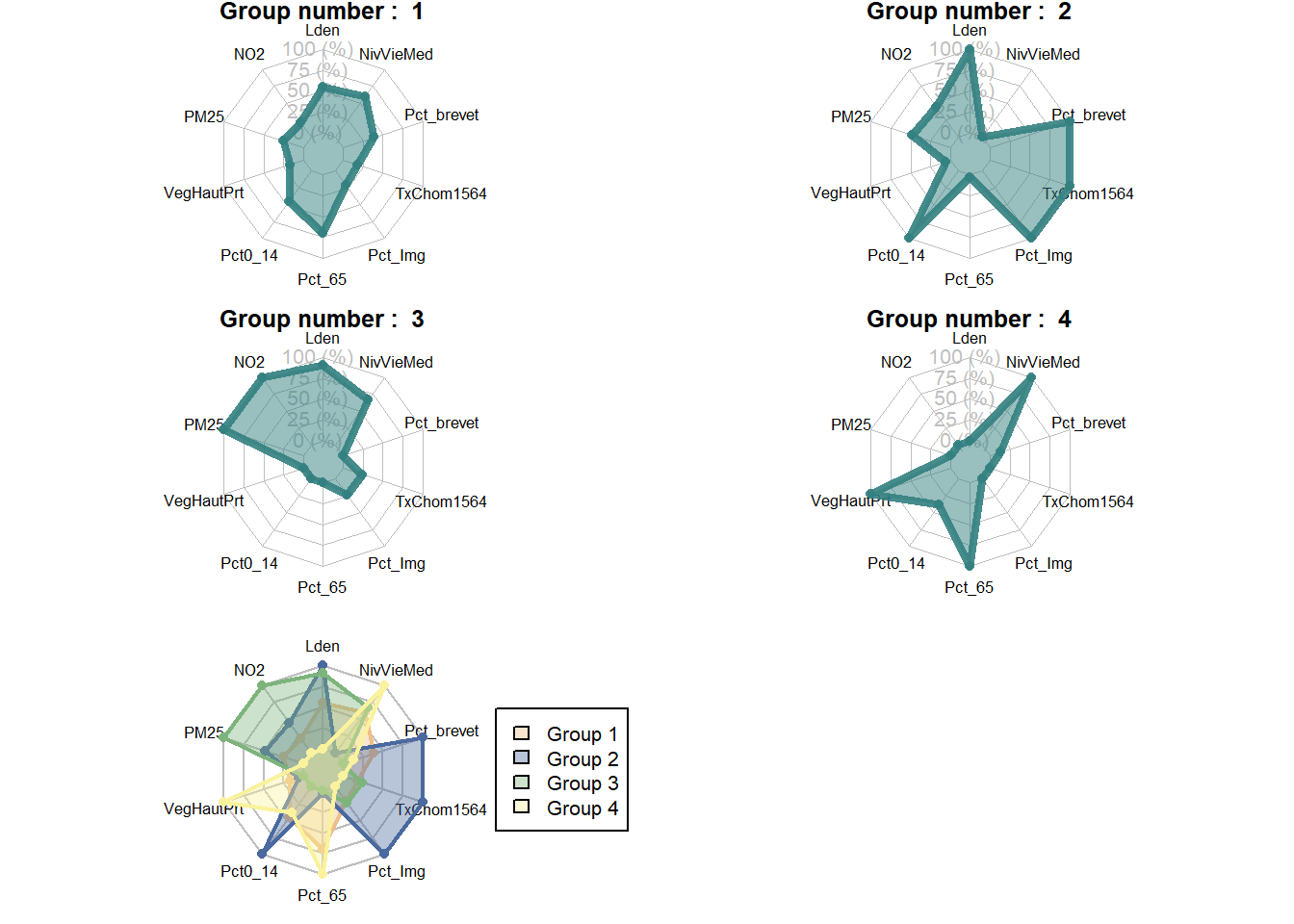
Figure 13.28: Graphique en radar pour les résultats du c-means
Sans surprise, nous retrouvons essentiellement les profils que nous avons obtenus avec le k-means dans la figure 13.28. Pour compléter la lecture des résultats, il est nécessaire de se pencher sur le tableau des statistiques descriptives des différents groupes. Une fois encore, nous proposons d’utiliser la fonction summarizeClusters du package geocmeans. Notez que cette fonction calcule les statistiques descriptives pondérées en fonction de l’appartenance des observations aux groupes. Ainsi, une observation ayant une faible chance d’appartenir à un groupe ne contribue que faiblement aux statistiques descriptives de ce groupe.
df <- st_drop_geometry(LyonIris[c("Lden","NO2","PM25","VegHautPrt","Pct0_14",
"Pct_65","Pct_Img", "TxChom1564",
"Pct_brevet","NivVieMed")])
tableaux <- summarizeClusters(data = df,
belongmatrix = cmeans_resultats$U,
weighted = TRUE, dec = 1)
tableau_tot <- do.call(rbind, tableaux)| Lden | NO2 | PM25 | VegHautPrt | Pct014 | Pct65 | PctImg | TxChom1564 | Pctbrevet | NivVieMed | |
|---|---|---|---|---|---|---|---|---|---|---|
| groupe 1 | ||||||||||
| Q5 | 48,7 | 15,8 | 13,5 | 6,2 | 12,2 | 9,5 | 4,3 | 6,7 | 10,7 | 16 191,5 |
| Q10 | 50,5 | 18,7 | 13,9 | 7,4 | 14,2 | 11,4 | 5,7 | 7,6 | 13,7 | 17 616,0 |
| Q25 | 52,4 | 20,9 | 14,7 | 11,4 | 16,8 | 14,2 | 7,8 | 9,3 | 18,4 | 19 559,0 |
| Q50 | 54,7 | 25,0 | 15,6 | 15,8 | 19,0 | 17,7 | 11,2 | 12,1 | 24,0 | 21 947,5 |
| Q75 | 57,6 | 28,6 | 16,8 | 22,3 | 21,3 | 21,1 | 15,6 | 15,1 | 29,8 | 24 069,2 |
| Q90 | 60,7 | 33,0 | 18,5 | 29,8 | 23,2 | 24,4 | 20,3 | 18,5 | 34,7 | 26 164,0 |
| Q95 | 63,1 | 37,8 | 19,0 | 34,3 | 25,4 | 27,5 | 23,5 | 22,3 | 39,0 | 28 931,0 |
| Mean | 55,1 | 25,4 | 15,8 | 17,5 | 18,9 | 17,9 | 12,4 | 13,0 | 24,7 | 21 951,6 |
| Std | 4,4 | 6,3 | 1,7 | 8,6 | 4,5 | 5,7 | 6,8 | 6,8 | 10,3 | 3 744,1 |
| groupe 2 | ||||||||||
| Q5 | 50,8 | 19,6 | 14,0 | 6,4 | 12,9 | 7,5 | 8,4 | 9,4 | 15,5 | 12 392,0 |
| Q10 | 52,1 | 21,4 | 14,6 | 7,7 | 16,6 | 8,8 | 12,9 | 13,0 | 22,0 | 12 920,0 |
| Q25 | 54,5 | 23,2 | 15,8 | 10,8 | 20,1 | 11,1 | 19,6 | 16,8 | 30,5 | 14 078,0 |
| Q50 | 57,1 | 26,6 | 16,6 | 14,5 | 23,6 | 13,9 | 25,8 | 22,0 | 37,5 | 15 985,0 |
| Q75 | 59,5 | 31,9 | 17,8 | 19,0 | 27,0 | 17,4 | 32,1 | 30,1 | 44,2 | 18 566,2 |
| Q90 | 63,3 | 37,4 | 18,8 | 25,4 | 29,7 | 20,7 | 37,8 | 33,9 | 48,6 | 21 146,0 |
| Q95 | 64,7 | 39,6 | 19,3 | 30,7 | 32,3 | 23,3 | 39,4 | 37,7 | 52,9 | 23 712,5 |
| Mean | 57,3 | 28,1 | 16,7 | 15,8 | 23,4 | 14,4 | 25,5 | 23,0 | 36,9 | 16 658,7 |
| Std | 4,4 | 6,6 | 1,6 | 7,6 | 6,3 | 5,1 | 9,7 | 9,3 | 12,3 | 3 611,9 |
| groupe 3 | ||||||||||
| Q5 | 50,6 | 27,5 | 16,3 | 6,2 | 8,6 | 6,8 | 6,0 | 7,6 | 7,5 | 16 976,0 |
| Q10 | 51,9 | 28,8 | 17,1 | 7,7 | 10,4 | 8,4 | 7,0 | 8,6 | 8,7 | 18 434,0 |
| Q25 | 53,8 | 30,9 | 18,3 | 10,2 | 12,6 | 10,8 | 9,1 | 11,1 | 11,0 | 19 785,0 |
| Q50 | 56,5 | 35,0 | 18,9 | 13,4 | 15,2 | 14,1 | 12,3 | 13,1 | 14,8 | 22 289,0 |
| Q75 | 59,4 | 38,7 | 19,6 | 17,6 | 17,9 | 17,5 | 15,9 | 15,5 | 21,5 | 24 522,0 |
| Q90 | 62,7 | 41,1 | 20,0 | 24,8 | 20,5 | 20,5 | 18,9 | 18,4 | 27,6 | 27 600,0 |
| Q95 | 64,3 | 44,3 | 20,2 | 30,6 | 21,8 | 23,5 | 21,0 | 20,6 | 32,2 | 29 732,8 |
| Mean | 56,8 | 34,9 | 18,7 | 14,8 | 15,3 | 14,2 | 12,8 | 13,7 | 16,9 | 22 595,1 |
| Std | 4,4 | 5,9 | 1,3 | 7,2 | 4,6 | 5,2 | 5,8 | 5,5 | 9,1 | 3 969,2 |
| groupe 4 | ||||||||||
| Q5 | 44,2 | 14,7 | 12,4 | 11,3 | 12,5 | 11,1 | 4,0 | 6,7 | 9,3 | 18 686,5 |
| Q10 | 45,7 | 15,6 | 12,9 | 16,4 | 14,1 | 13,0 | 4,5 | 7,2 | 11,2 | 20 220,0 |
| Q25 | 49,3 | 18,7 | 13,7 | 24,7 | 16,5 | 15,8 | 5,8 | 7,9 | 14,2 | 22 622,0 |
| Q50 | 52,3 | 22,0 | 14,6 | 30,4 | 18,6 | 19,0 | 7,5 | 9,7 | 17,9 | 24 843,0 |
| Q75 | 55,1 | 26,3 | 15,9 | 37,9 | 20,8 | 22,3 | 10,1 | 12,1 | 22,8 | 28 590,0 |
| Q90 | 58,9 | 30,9 | 17,1 | 42,3 | 22,4 | 27,2 | 14,4 | 15,3 | 30,1 | 31 294,0 |
| Q95 | 60,8 | 34,5 | 18,3 | 45,7 | 23,2 | 28,9 | 19,3 | 18,6 | 33,2 | 34 574,0 |
| Mean | 52,3 | 22,8 | 14,9 | 30,3 | 18,4 | 19,4 | 8,8 | 10,9 | 19,5 | 25 547,4 |
| Std | 5,1 | 6,3 | 1,7 | 10,0 | 4,1 | 5,9 | 5,5 | 6,2 | 9,2 | 4 603,5 |
13.4.5.2 Mise en oeuvre du c-medoids dans R
La méthode du c-medoids dans R peut être mise en oeuvre avec la fonction FKM.med du package fclust. Le processus d’analyse et de validation est identique à celui présenté ci-dessus pour le c-means. Nous ne donnons donc pas un exemple complet de la méthode.
Stabilité des groupes obtenus par les méthodes de nuées dynamiques :
Puisque la méthode k-means et ses variantes reposent sur une initialisation aléatoire de leur algorithme, les résultats peuvent varier en fonction de cet état de départ. Dans certains contextes, il est possible que les résultats obtenus varient significativement, ce qui signifie que les groupes obtenus ne sont pas représentatifs de la population étudiée. Une solution pour vérifier si ce problème se pose est simplement de relancer l’algorithme un grand nombre de fois (généralement 1000) et de comparer les résultats obtenus au cours de ces réplications.
Cette méthode est rarement implémentée directement et requiert d’écrire sa propre fonction. geocmeans dispose d’une fonction déjà existante, mais ne pouvant être appliquée qu’avec l’algorithme c-means. Nous proposons ici une implémentation pour la méthode k-means qui peut facilement être adaptée aux autres méthodes de classifications heuristiques.
La démarche à suivre est la suivante :
- Appliquer l’algorithme une première fois pour obtenir une classification de référence à laquelle nous comparerons toutes les réplications.
- Effectuer 1000 itérations au cours desquelles :
- Une nouvelle classification est calculée.
- Les groupes obtenus sont comparés à ceux de la classification de référence.
- L’indice de Jacard est calculé entre les groupes des deux classifications.
- Les valeurs de l’indice de Jacard sont enregistrées.
- Les centres des groupes sont enregistrés.
Ainsi, nous obtenons 1000 valeurs de l’indice de Jacard pour chaque groupe. Cet indice permet de mesurer le degré d’accord entre deux variables (ici les probabilités d’appartenance des observations au même groupe pour deux classifications différentes.) Une valeur moyenne en dessous de 0,5 indique qu’un groupe est très instable, car nous obtenons des résultats très différents lors des réplications. Une valeur entre 0,6 et 0,75 indique qu’un groupe semble bien exister dans les données, bien que marqué par une certaine incertitude. Une valeur au-dessus de 0,8 indique un groupe bien identifié et stable.
Nous obtenons également les centres des groupes des 1000 classifications. Il est ainsi possible de représenter leurs histogrammes et de déterminer si les centres des groupes sont stables (unimodalité et faible variance) ou incertains (plusieurs modes et/ou forte variance).
# X sera le jeu de données pour la classification
# clust_ref sera le vecteur indiquant le groupe de chaque observation obtenu par kmeans
# nsim sera le nombre de simulations à effectuer
kmeans_stability <- function(X, clust_ref, nsim, verbose = TRUE){
# définition de la matrice d'appartenance originale
k <- length(unique(clust_ref))
ref_mat <- dummy_cols(clust_ref, remove_selected_columns = TRUE)
colnames(ref_mat) <- paste0("groupe_",1:k)
# lancement des itérations
sim_resultats <- lapply(1:nsim, function(i){
# afficher la progression si requis
if(verbose){
print(paste0("iteration numeros : ",i,"/",nsim))
}
# calculer le kmeans
km_res <- kmeans(X,k)
sim_mat <- dummy_cols(km_res$cluster, remove_selected_columns = TRUE)
# ajustement de l'ordre des groupes avec geocmeans
sim_mat <- groups_matching(as.matrix(ref_mat), as.matrix(sim_mat))
# calcul des indices de jacard
jac_idx <- sapply(1:k, function(j){
calc_jaccard_idx(sim_mat[,j], ref_mat[,j])
})
# recuperation des centres des groupes
idx <- as.integer(gsub(".data_","",colnames(sim_mat),fixed = TRUE))
centers <- data.frame(km_res$centers)
centers <- centers[idx,]
centers$groupe <- 1:k
return(list(
"jac_idx" = jac_idx,
"centers" = centers
))
})
# les simulations sont finies, nous pouvons combiner les resultats
all_jac_values <- do.call(rbind, lapply(sim_resultats, function(x){x$jac_idx}))
all_centers <- do.call(rbind, lapply(sim_resultats, function(x){x$centers}))
return(list(
"jacard_values" = all_jac_values,
"centers" = all_centers
))
}Il ne nous reste plus qu’à utiliser notre nouvelle fonction pour déterminer si les groupes obtenus avec notre k-means sont stables.
data(LyonIris)
set.seed(123)
# NB : LyonIris est un objet spatial, il faut donc extraire uniquement son DataFrame
X <- st_drop_geometry(LyonIris[c("Lden","NO2","PM25","VegHautPrt","Pct0_14","Pct_65","Pct_Img",
"TxChom1564","Pct_brevet","NivVieMed")])
# Centrage et réduction de chaque colonne du DataFrame
for (col in names(X)){
X[[col]] <- scale(X[[col]], center = TRUE, scale = TRUE)
}
# calcul du kmeans de référence
kmeans_ref <- kmeans(X, 4)
# application de la fonction de stabilité
stab_results <- kmeans_stability(X, kmeans_ref$cluster, nsim = 1000, verbose = FALSE)Nous pouvons à présent vérifier la stabilité de nos quatre groupes.
jacard_values <- data.frame(stab_results$jacard_values)
names(jacard_values) <- paste("groupe", 1:4, sep = "_")
df <- reshape2::melt(jacard_values)
df$groupes <- as.factor(df$variable)
ggplot(df) +
geom_histogram(aes(x = value), bins = 30) +
facet_wrap(vars(groupes), ncol=2) +
labs(x = "", y = "Indice de Jacard")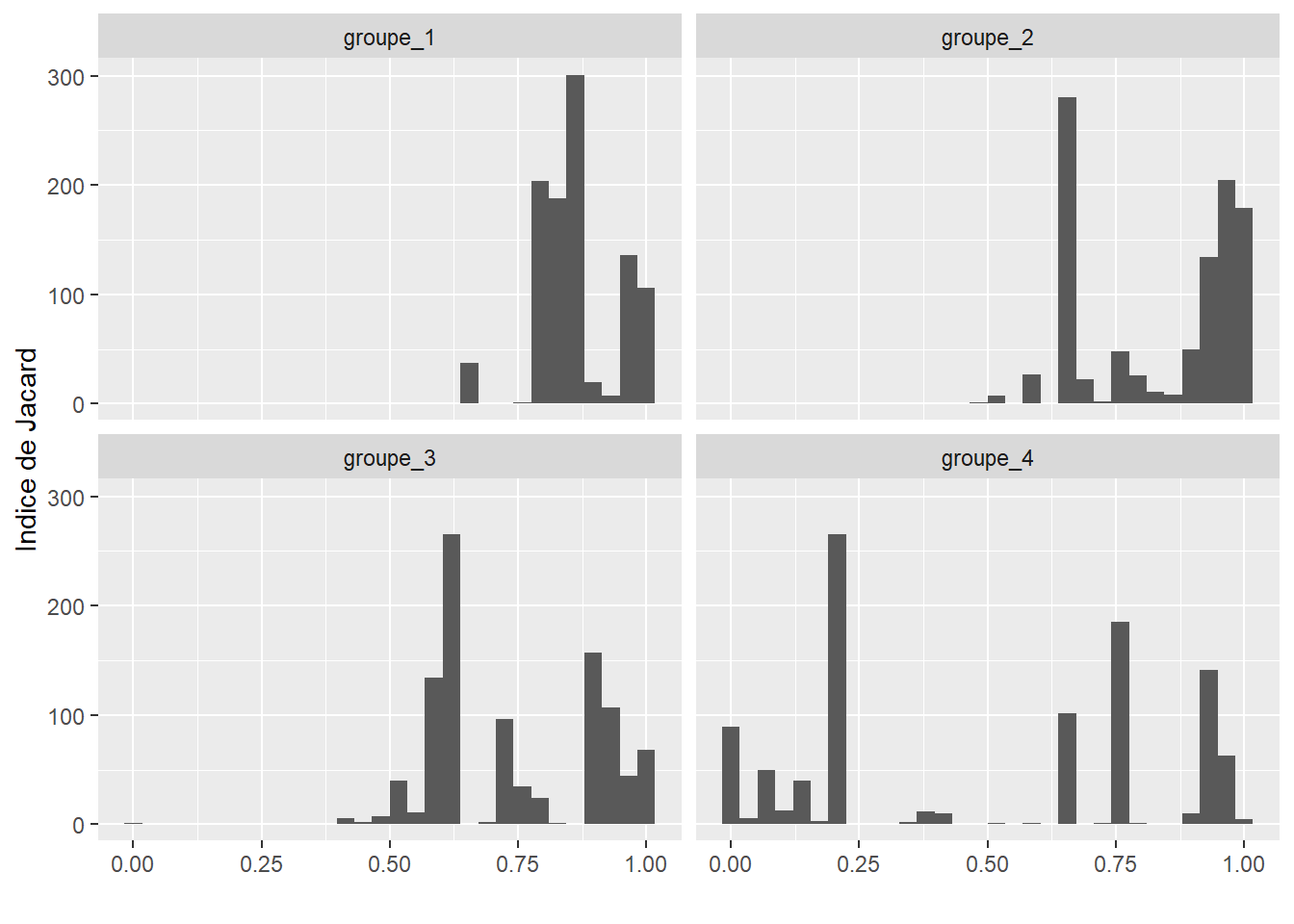
Figure 13.29: Indices de Jacard obtenus sur 1000 réplications du k-means
La figure 13.29 indique clairement que les groupes 1 et 2 sont très stables, car les valeurs de Jacard obtenues sont le plus souvent supérieures à 0,75. Le groupe 3 a le plus souvent des valeurs légèrement inférieures aux deux premiers groupes, mais tout de même bien supérieures à 0,5. En revanche, le groupe 4 a un grand nombre de valeurs inférieures à 0,5 indiquant une tendance du groupe à se dissoudre lors des réplications.
Considérant que le dernier groupe est le plus instable, nous décidons d’observer les valeurs des centres qu’il obtient pour les différentes réplications.
centers_groupe4 <- subset(stab_results$centers, stab_results$centers$groupe == 4)
centers_groupe4$groupe <- NULL
df <- reshape2::melt(centers_groupe4)
df$variable <- as.factor(df$variable)
ggplot(df) +
geom_histogram(aes(x = value), bins = 30) +
facet_wrap(vars(variable), ncol=3, scales="free") +
labs(x = "", y = "")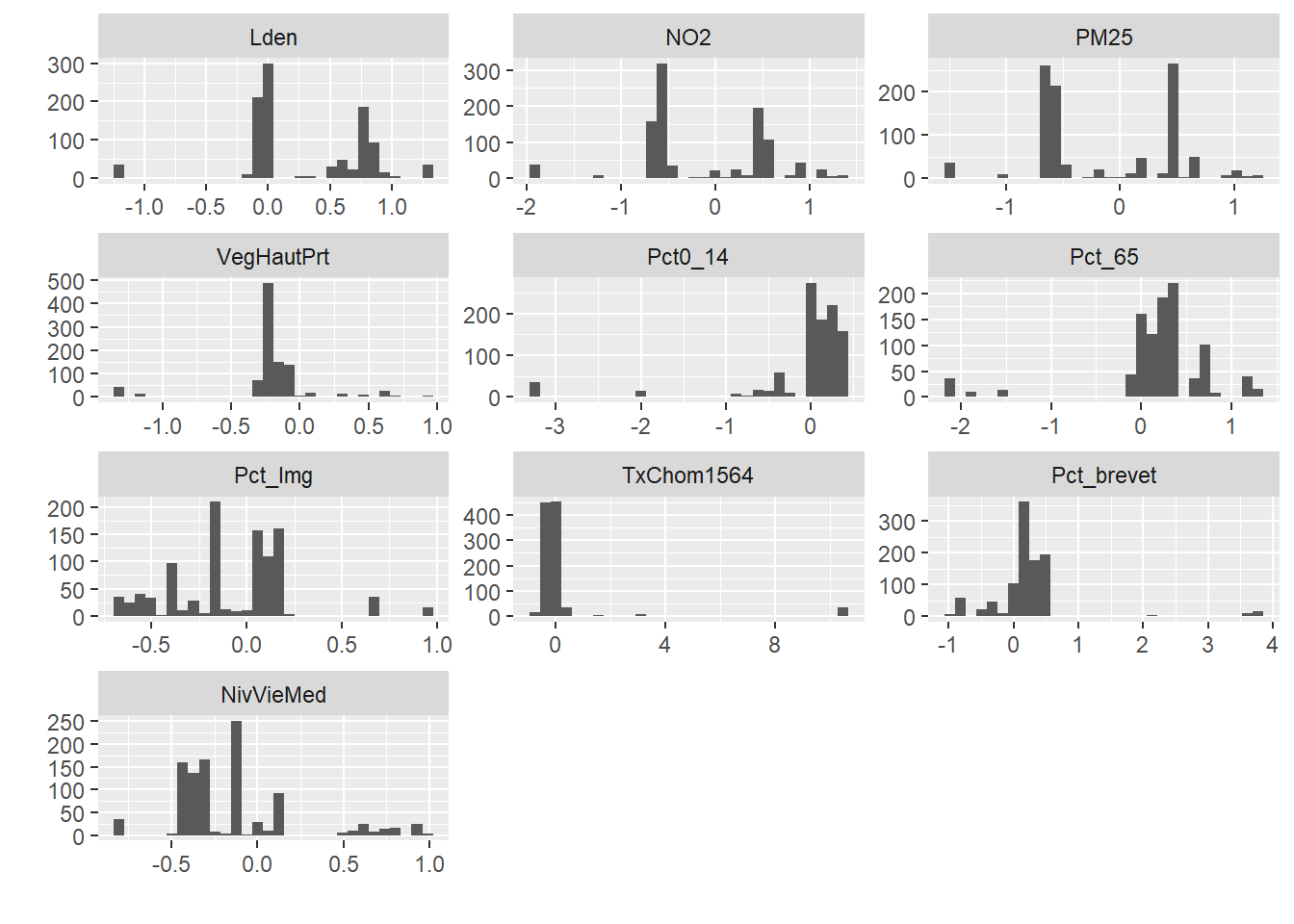
Figure 13.30: Distributions des valeurs des centres du groupe 4 sur 1000 itérations
Les différents histogrammes de la figure 13.30 indiquent clairement que pour plusieurs variables (Lden, NO2, PM25, Pct_Img, et NivVieMed) les caractéristiques du groupe 4 varient grandement sur l’ensemble des réplications. Nous pouvons comparer ce graphique à celui du groupe 2 qui est bien plus stable.
centers_groupe2 <- subset(stab_results$centers, stab_results$centers$groupe == 2)
centers_groupe2$groupe <- NULL
df <- reshape2::melt(centers_groupe2)
df$variable <- as.factor(df$variable)
ggplot(df) +
geom_histogram(aes(x = value), bins = 30) +
facet_wrap(vars(variable), ncol=3, scales="free") +
labs(x = "", y = "")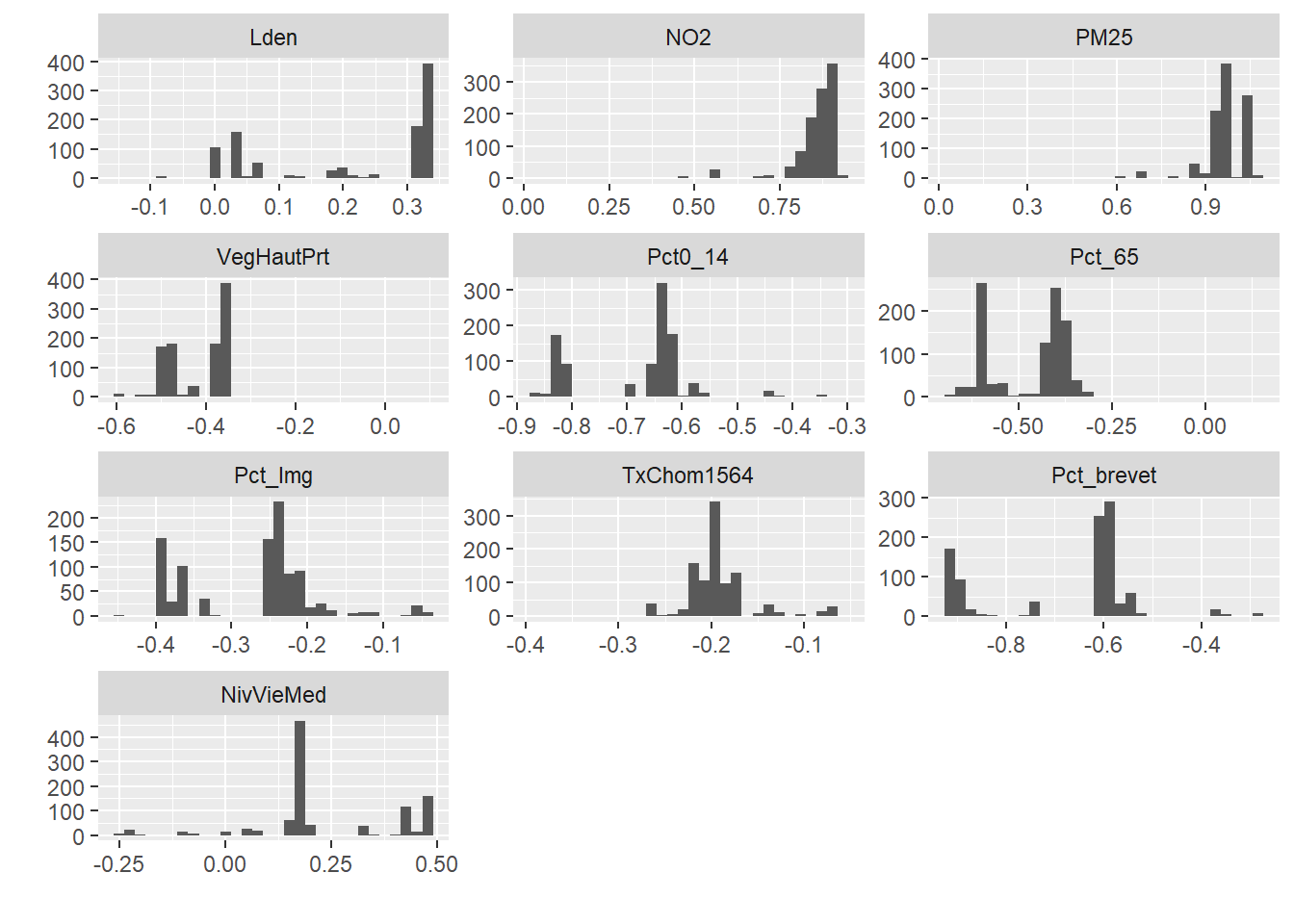
Figure 13.31: Distributions des valeurs des centres du groupe 2 sur 1000 itérations
Nous pouvons constater une plus faible variance des résultats obtenus (en regardant notamment l’axe horizontal) pour les centres des groupes à la figure 13.31.