13.1 Méthodes de classification : un aperçu
Il existe une multitude de méthodes de classification généralement regroupées dans plusieurs familles imbriquées à partir de deux distinctions importantes.
La première distinction vise à séparer les méthodes supervisées des non supervisées. Pour les premières, les catégories/groupes/classes des observations sont connues à l’avance. L’enjeu n’est pas de trouver les catégories puisqu’elles sont connues, mais de déterminer des règles ou un modèle permettant d’attribuer des observations à ces catégories. Parmi les méthodes de classification supervisée, les plus connues sont les forêts d’arbres décisionnels, les réseaux de neurones artificiels ou encore l’analyse factorielle discriminante. Nous n’abordons pas ces méthodes dans ce chapitre dédié uniquement aux méthodes de classification non supervisée. Pour ces dernières, les catégories ne sont pas connues à l’avance et l’enjeu est de faire ressortir les structures des groupes propres aux données. Ainsi, les méthodes de classification non supervisée « relèvent de la statistique exploratoire multidimensionnelle et permettent de classifier automatiquement les observations sans connaissance a priori sur la nature des classes présentes dans le jeu de données; les plus connues sont sans conteste les algorithmes de classification ascendante hiérarchique (CAH) et du k-means (k-moyennes) » (Gelb et Apparicio 2021b, 1). Notez également qu’à la frontière entre ces deux familles, se situent les méthodes de classification semi-supervisée. Il s’agit de cas spécifiques où des informations partielles sont connues sur les groupes à détecter : seulement le groupe final de certaines observations est connu, certaines observations sont supposées appartenir à un même groupe même s’il est indéfini en lui-même (Bair 2013).
La seconde distinction vise à séparer les méthodes strictes des floues. Les premières ont pour objectif d’assigner chaque observation à une et une seule catégorie, alors que les secondes décrivent le degré d’appartenance de chaque observation à chaque catégorie. Autrement dit, « dans une classification stricte, chaque observation appartient à une seule classe. Mathématiquement parlant, l’appartenance à une classe donnée est binaire (0 ou 1) tandis que dans une classification floue, chaque observation a une probabilité d’appartenance variant de 0 à 1 à chacune des classes » (Gelb et Apparicio 2021b, 1). Bien entendu, pour chaque observation, la somme des degrés d’appartenance à chacune des classes est égale à 1 (figure 13.2). En termes de données, cela signifie que pour les méthodes strictes, le groupe d’appartenance d’une observation est contenu dans une seule variable nominale (une colonne d’un DataFrame). Pour les méthodes floues, il est nécessaire de disposer d’autant de variables continues (plusieurs colonnes numériques d’un DataFrame), soit une par groupe, dans lesquelles est enregistré le degré d’appartenance de chaque observation à chacun des groupes. Parmi les méthodes de classification supervisée floue, notez que nous avons déjà abordé la régression logistique multinomiale dans le chapitre sur les GLM (section 8.2.4).
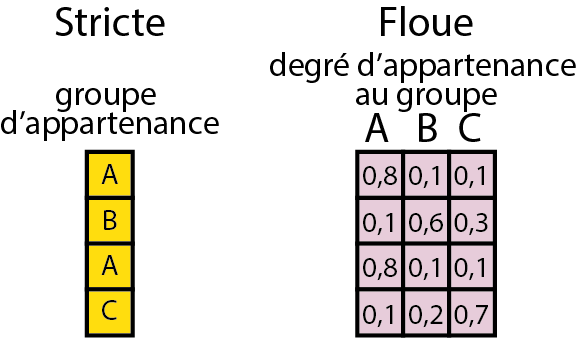
Figure 13.2: Classifications stricte et floue
En résumé, le croisement de ces deux distinctions permet ainsi de différencier les méthodes supervisées strictes, supervisées floues, non supervisées strictes et non supervisées floues (figure 13.3), auxquelles s’ajoutent les méthodes semi-supervisées discutées brièvement.
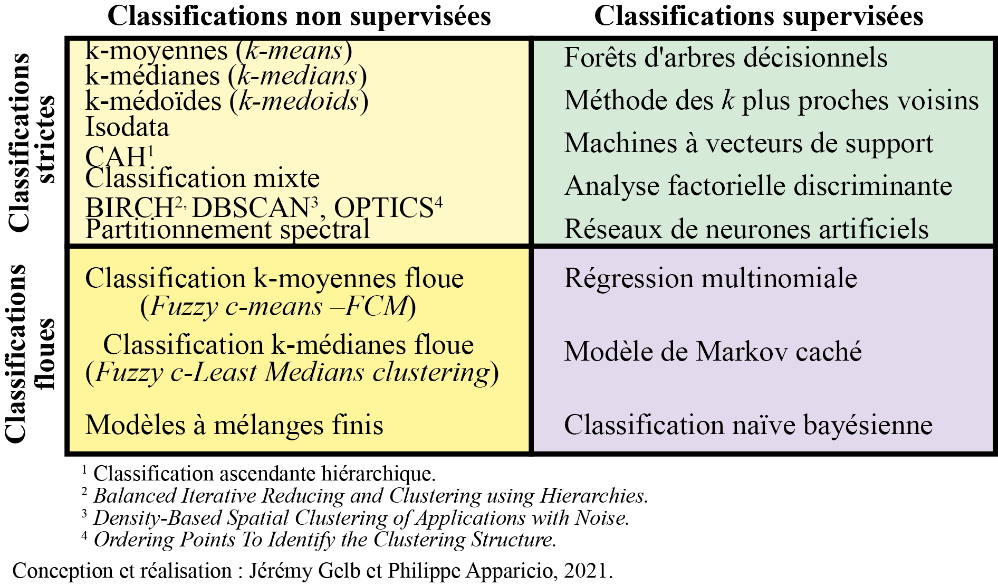
Figure 13.3: Synthèse des principales méthodes de classification (Gelb et Apparicio 2021)
Dans ce chapitre, nous décrivons les trois méthodes de classification non supervisée les plus utilisées et faciles à mettre en œuvre : la classification ascendante hiérarchique, les nuées dynamiques strictes (k-means et k-medians) et nuées dynamiques floues (c-means et c-medians).