11.7 GAMM
Bien entendu, il est possible de combiner les modèles généralisés additifs (GAM) avec les modèles à effet mixtes (GLMM) abordés dans les sections précédentes. Ces modèles généralisés additifs à effets mixtes (GAMM) peuvent facilement être mis en œuvre avec mgcv.
11.7.0.1 GAMM et interceptes aléatoires
Pour définir des constantes aléatoires, il suffit d’utiliser la notation s(var, bs = 're') avec var une variable nominale. Reprenons l’exemple précédent, mais avec cette fois-ci les arrondissements comme un intercepte aléatoire.
dataset$Arrond <- as.factor(dataset$Arrond)
model4 <- gam(hot ~
A65Pct + A014Pct + PopFRPct + PopMVPct +
s(prt_veg) + s(Arrond, bs = "re"),
data = dataset, family = betar(link = "logit"))L’enjeu est ensuite d’extraire la variance propre à cet effet aléatoire ainsi que les valeurs des interceptes pour chaque arrondissement.
gam.vcomp(model4)##
## Standard deviations and 0.95 confidence intervals:
##
## std.dev lower upper
## s(prt_veg) 0.007047166 0.003785275 0.01311993
## s(Arrond) 0.393539474 0.302707198 0.51162747
##
## Rank: 2/2Nous constatons donc que l’écart-type de l’effet aléatoire des arrondissements est de 0,39, ce qui signifie que les effets de chaque arrondissement seront compris à 95 % entre -1,17 et 1,17 (1.17 = 3*0.39) sur l’échelle du prédicteur linéaire. En effet, rappelons que les effets aléatoires sont modélisés comme des distributions normales et que 95 % de la densité d’une distribution normale se situe entre -3 et +3 écarts-types. Pour extraire les interceptes spécifiques de chaque arrondissement, nous pouvons utiliser la fonction get_random du package itsadug.
library(itsadug)
values <- get_random(model4)[[1]]
df <- data.frame(
ri = as.numeric(values),
arrond = names(values)
)
ggplot(df) +
geom_point(aes(x = ri, y = reorder(arrond, ri))) +
geom_vline(xintercept = 0, color = "red") +
labs(y = "Arrondissement", x = "intercepte aléatoire")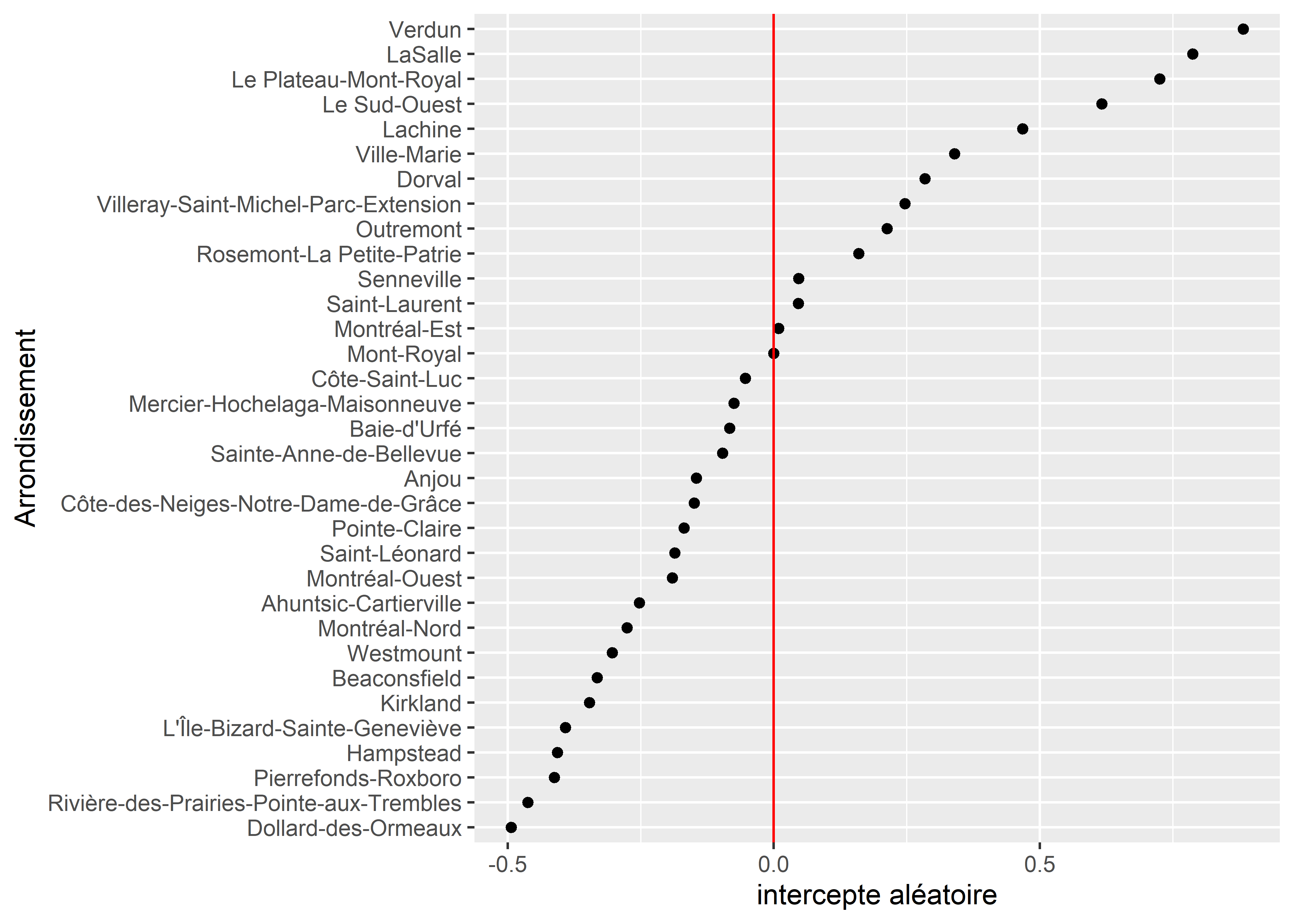
Figure 11.18: Constantes aléatoires pour les arrondissements
Nous constatons ainsi, à la figure 11.18, que pour une partie des arrondissements, la densité d’îlot de chaleur est systématiquement supérieure à la moyenne régionale représentée ici par la ligne rouge (0 = effet moyen pour tous les arrondissements). Il convient alors d’améliorer ce graphique en ajoutant le niveau d’incertitude associé à chaque intercepte. Pour ce faire, nous utilisons la fonction extract_random_effects du package mixedup. Notez que ce package n’est actuellement pas disponible sur CRAN et doit être téléchargé sur github avec la commande suivante :
remotes::install_github('m-clark/mixedup')Avec la version 4.0.1 de R, nous avons rencontré des difficultés pour installer mixedup. Nous avons donc simplement récupéré le code source de la fonction et l’avons enregistré dans un fichier de code séparé que nous appelons ici.
source("code_complementaire/gam_functions.R")Nous pouvons ensuite procéder à l’extraction des effets aléatoires et les représenter à nouveau (figure 11.19).
df_re <- extract_random_effects.gam(model4, re = "Arrond")
ggplot(df_re) +
geom_errorbarh(aes(xmin = lower_2.5, xmax = upper_97.5, y = reorder(group, value))) +
geom_point(aes(x = value, y = reorder(group, value))) +
geom_vline(xintercept = 0, color = "red") +
labs(y = "Arrondissement", x = "Intercepte aléatoire")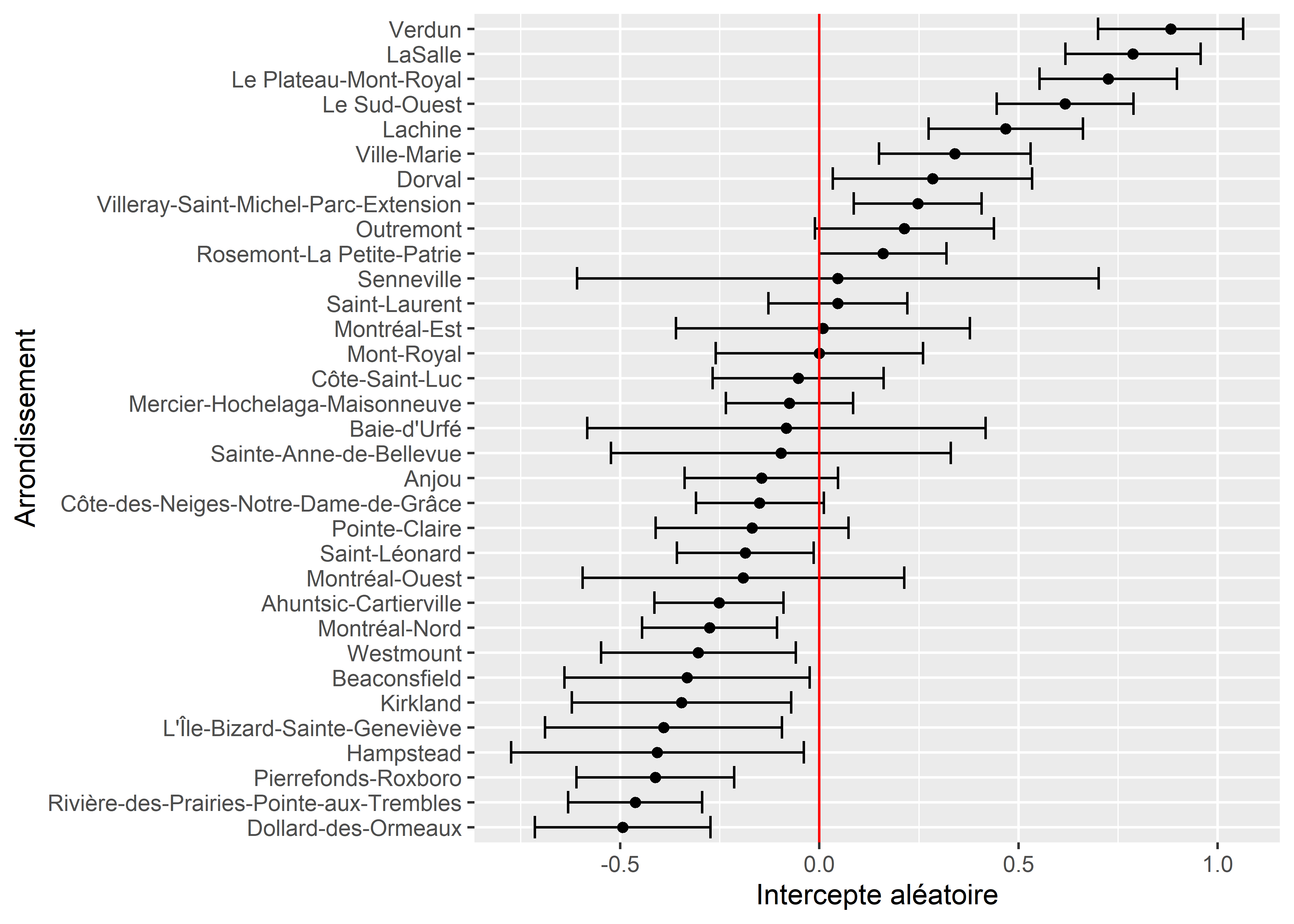
Figure 11.19: Constantes aléatoires pour les arrondissements avec intervalle de confiance
Cela permet de distinguer quels écarts sont significativement différents de 0 au seuil de 95 %. À titre de rappel, pour être significatif à ce seuil, un intervalle représenté par une ligne noire horizontale ne doit pas intersecter la ligne rouge verticale. Puisque nous utilisons ici la distribution bêta et une fonction de lien logistique, nous devons utiliser des prédictions pour simplifier l’interprétation des coefficients. Nous fixons ici toutes les variables à leur moyenne respective, sauf l’arrondissement, et calculons les prédictions dans l’échelle originale (0 à 1).
dfpred <- data.frame(
A65Pct = mean(dataset$A65Pct),
A014Pct = mean(dataset$A014Pct),
PopFRPct = mean(dataset$PopFRPct),
PopMVPct = mean(dataset$PopMVPct),
prt_veg = mean(dataset$prt_veg),
Arrond = as.character(unique(dataset$Arrond))
)
# Calculer les prédictions pour le prédicteur linéaire
dfpred$preds <- predict(model4, newdata = dfpred, type = "link")
# Calculer l'intervalle de confiance en utilisant les valeurs
# extraites avec extract_random_effects
dfpred <- dfpred[order(dfpred$Arrond),]
df_re <- df_re[order(df_re$group),]
dfpred$lower <- dfpred$preds - 1.96*df_re$se
dfpred$upper <- dfpred$preds + 1.96*df_re$se
# Il nous reste juste à reconvertir le tout dans l'unité d'origine
# en utilisant l'inverse de la fonction logistique
inv.logit <- function(x){exp(x)/(1+exp(x))}
dfpred$lower <- inv.logit(dfpred$lower)
dfpred$upper <- inv.logit(dfpred$upper)
dfpred$preds <- inv.logit(dfpred$preds)
ggplot(dfpred) +
geom_errorbarh(aes(xmin = lower, xmax = upper, y = reorder(Arrond, preds))) +
geom_point(aes(x = preds, y = reorder(Arrond, preds))) +
geom_vline(xintercept = mean(dfpred$preds), color = "red") +
labs(y = "Arrondissement", x = "intercepte aléatoire")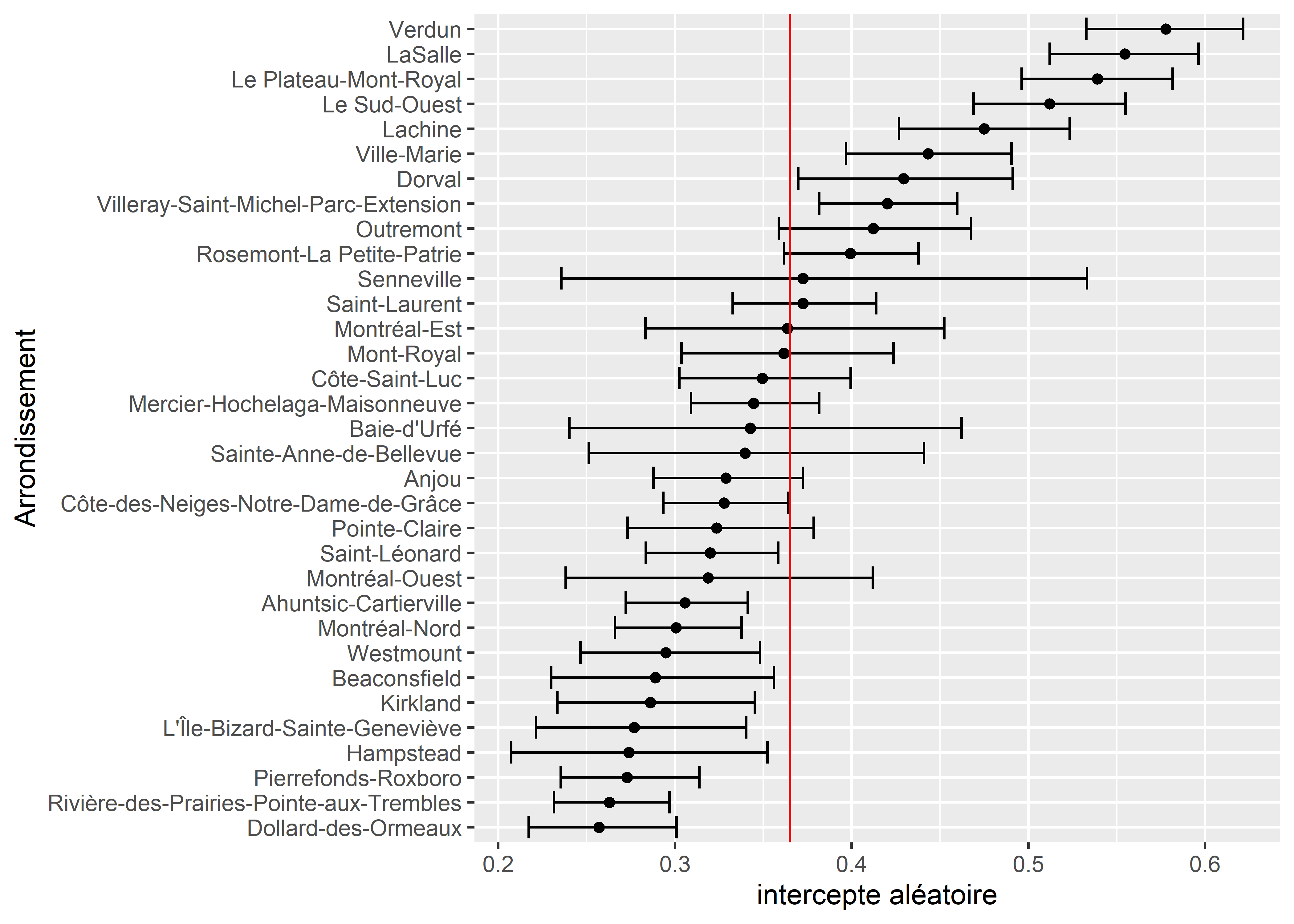
Figure 11.20: Prédictions pour les différents arrondissements pour une AD fictive moyenne
Nous constatons ainsi, à la figure 11.20, que pour une hypothétique aire de diffusion moyenne, la différence de densité d’îlot de chaleur peut être de 0,32 (32 % de la surface de l’AD) entre les arrondissements Verdun et Dollard-des-Ormeaux.
11.7.0.2 GAMM et coefficients aléatoires
En plus des interceptes aléatoires, il est aussi possible de définir des coefficients aléatoires. Reprenons notre exemple et tentons de faire varier l’effet de la variable PopFRPct en fonction de l’arrondissement.
model5 <- gam(hot ~
A65Pct + A014Pct + PopFRPct + PopMVPct +
s(prt_veg) + s(Arrond, bs = "re") +
s(PopFRPct, Arrond, bs = "re"),
data = dataset, family = betar(link = "logit"))Notez ici une distinction importante! Le modèle n’assume aucune corrélation entre les coefficients aléatoires pour la variable PopFRPct et pour les constantes aléatoires. Il est présumé que ces deux effets proviennent de deux distributions normales distinctes. En d’autres termes, le modèle ne dispose pas des paramètres nécessaires pour vérifier si les arrondissements avec les constantes les plus fortes (avec des densités supérieures d’îlot de chaleur) sont aussi des arrondissements dans lesquels l’effet de la variable PopFRPct est plus prononcé (et vice-versa). Pour plus d’informations sur cette distinction, référez-vous à la section 9.2.3.
AIC(model4, model5)## df AIC
## model4 41.54635 -6421.791
## model5 56.84734 -6466.726Ce dernier modèle présente une valeur de l’AIC plus faible et serait donc ainsi mieux ajusté que notre modèle avec seulement un intercepte aléatoire. Nous pouvons donc extraire les coefficients aléatoires et les représenter à la figure 11.21.
df_re <- extract_random_effects.gam(model5)
df_re <- subset(df_re, df_re$effect == 'PopFRPct')
ggplot(df_re) +
geom_errorbarh(aes(xmin = lower_2.5, xmax = upper_97.5, y = reorder(group, value))) +
geom_point(aes(x = value, y = reorder(group, value))) +
geom_vline(xintercept = 0, color = "red") +
labs(y = "Arrondissement", x = "coefficient aléatoire")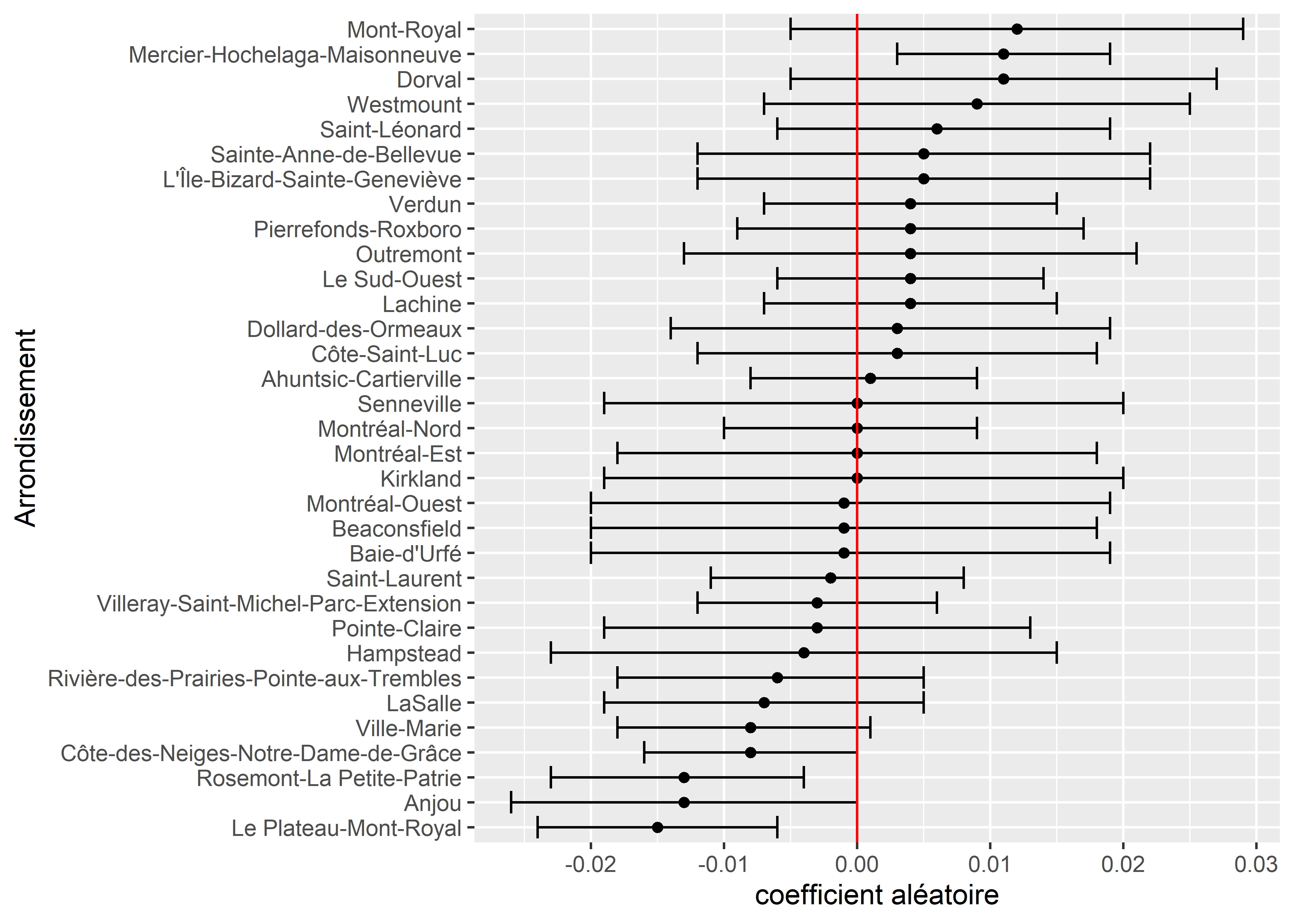
Figure 11.21: Pentes et constantes aléatoires pour les arrondissements
Nous constatons notamment que seuls trois arrondissements ont des coefficients aléatoires significativement différents de 0. Ainsi, pour les arrondissements Anjou et Plateau-Mont-Royal, les coefficients aléatoires sont respectivement de -0,013 et -0,015, et viennent donc se retrancher à la valeur moyenne régionale de 0,0154 qui atteint alors presque 0. Du point de vue de l’interprétation, nous pouvons en conclure que le groupe des personnes à faible revenu ne subit pas de surexposition aux îlots de chaleur à l’échelle des AD dans ces arrondissements.
En revanche, dans l’arrondissement Mercier-Hochelaga-Maisonneuve, la situation est à l’inverse plus systématiquement en défaveur des populations à faible revenu, avec une taille d’effet près de deux fois supérieure à la moyenne régionale. En effet, l’effet moyen régional (coefficient fixe) est de 0,0154, auquel vient s’ajouter l’effet spécifique (coefficient aléatoire) de Mercier-Hochelaga-Maisonneuve, soit 0,011, pour un effet total de 0,0264
Des effets aléatoires plus complexes dans les GAMM
Il est possible de spécifier des GAMM avec des effets aléatoires plus complexes autorisant, par exemple, des corrélations entre les différents effets / niveaux. Il faut pour cela utiliser la fonction gamm de mgcv ou la fonction gamm4 du package gamm4. La première offre plus de flexibilité, mais la seconde est plus facile à utiliser et doit être privilégiée quand un modèle comporte un très grand nombre de groupes dans un effet aléatoire, ou lorsque la distribution du modèle n’est pas gaussienne. La fonction gamm permet d’ajuster des modèles non gaussiens, mais elle utilise une approche appelée PQL (Penalized Quasi-Likelihood en anglais) connue pour être moins stable et moins précise.
Cependant, dans l’exemple de cette section, nous utilisons un modèle GAMM avec une distribution bêta, ce qui n’est actuellement pas supporté par les fonctions gamm et gamm4. Pour un modèle GAMM plus complexe utilisant une distribution bêta, il est nécessaire d’utiliser le package gamlss, mais ce dernier utilise aussi une approche de type PQL. Nous montrons tout de même ici comment ajouter un modèle qui inclut une corrélation entre les deux effets aléatoires de l’exemple précédent. Notez ici que le terme re apparaissant dans la formule permet de spécifier un effet aléatoire en utilisant la syntaxe du package nlme. Plus spécifiquement, gamlss fait un pont avec nlme et utilise son algorithme d’ajustement au sein de ces propres routines. De même, le terme pb permet de spécifier une spline de lissage dans le même esprit que mgcv. Il est également possible d’utiliser le terme ga faisant le lien avec mgcv et de profiter de sa flexibilité dans gamlss.
library(gamlss)
library(gamlss.add)
model6 <- gamlss(hot ~
pb(prt_veg) +
re(fixed = ~ A65Pct + A014Pct + PopFRPct + PopMVPct,
random = ~(1 + PopFRPct)|Arrond),
data = dataset, family = BE(mu.link = "logit"))Nous pouvons ensuite accéder à la partie du modèle qui nous intéresse, soit celle concernant les effets aléatoires.
randomPart <- model6$mu.coefSmo[[2]]
print(randomPart)## Linear mixed-effects model fit by maximum likelihood
## Data: Data
## Log-likelihood: -2964.494
## Fixed: fix.formula
## (Intercept) A65Pct A014Pct PopFRPct PopMVPct
## -0.060862832 -0.001945204 -0.010139278 0.017259606 -0.002599745
##
## Random effects:
## Formula: ~(1 + PopFRPct) | Arrond
## Structure: General positive-definite, Log-Cholesky parametrization
## StdDev Corr
## (Intercept) 0.47298363 (Intr)
## PopFRPct 0.01078909 -0.646
## Residual 0.99888012
##
## Variance function:
## Structure: fixed weights
## Formula: ~W.var
## Number of Observations: 3157
## Number of Groups: 33À lecture de la partie du résumé consacrée aux résultats pour les effets aléatoires, nous constatons que la corrélation entre les interceptes aléatoires et les coefficients aléatoires est de -0,65. Cela signifie que pour les arrondissements avec des interceptes élevés (plus grande proportion d’îlots de chaleur), l’effet de la variable PopFRPct tend à être plus faible. Autrement dit, dans les arrondissements avec beaucoup d’îlots de chaleur, les personnes à faible revenu ont tendance à être moins exposées, tel qu’illustré à la figure 11.22.
df <- ranef(randomPart)
df$arrond <- rownames(df)
names(df) <- c('Intercept', 'PopFRPct', 'Arrondissement')
ggplot(df) +
geom_hline(yintercept = 0, color = "red") +
geom_vline(xintercept = 0, color = "red") +
geom_point(aes(x = Intercept, y = PopFRPct))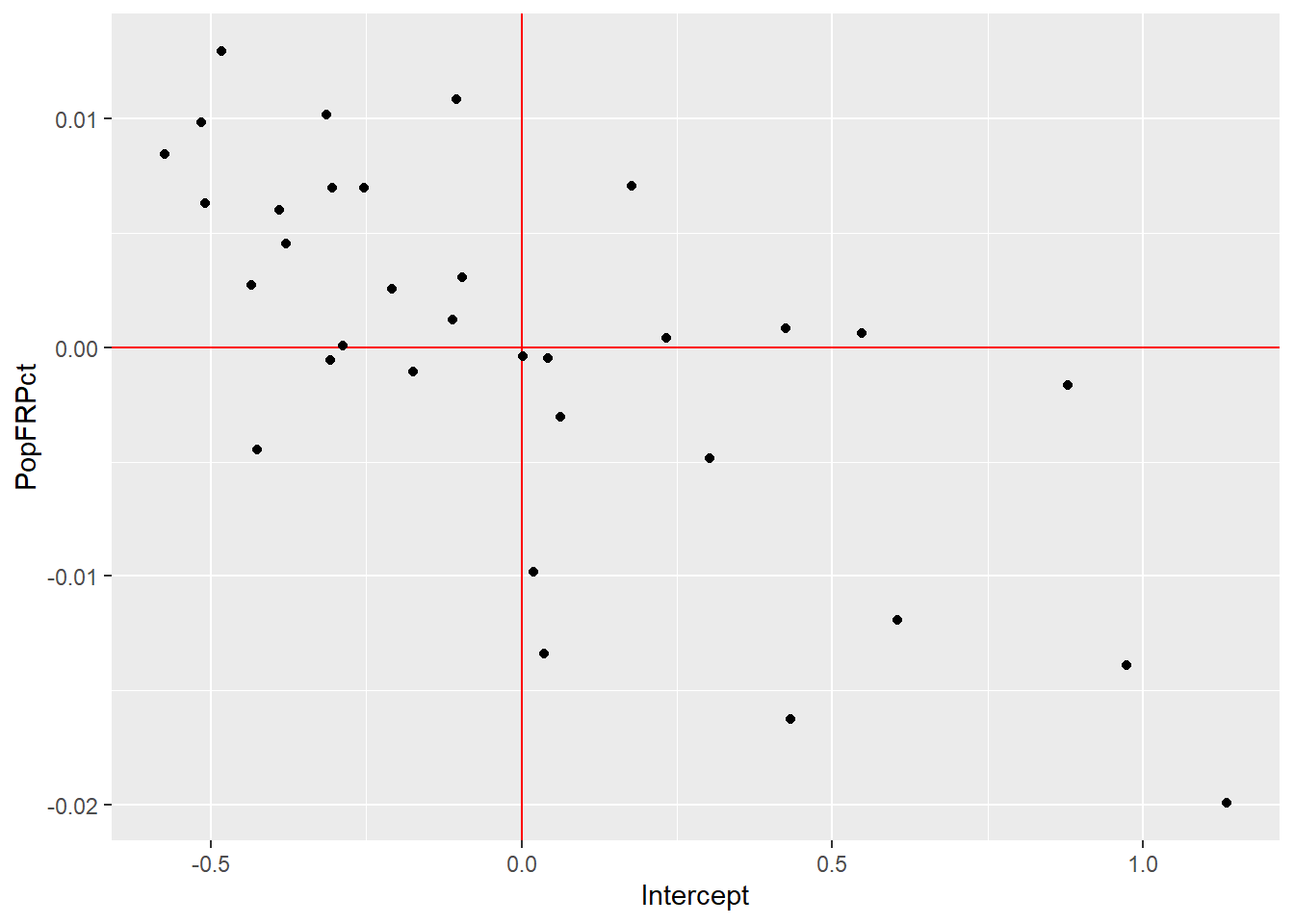
Figure 11.22: Relation entre les effets aléatoires des arrondissements et la variable population à faible revenu